
学习导图
1.简介和安装
MySQL、SQLite、PostgreSQL、SQL Server 、Oracle、达梦均属于关系型数据库(RDBMS),按照固定的结构存储数据(建表),数据可能依赖内存缓存加速,但最终都存储在硬盘里。遵循国际标准组织制定的 SQL 语法规范(如 SELECT、INSERT、JOIN等)。这保证了基础语法的高度一致性。
非关系型数据库(NoSQL):没有传统关系型数据库的固定表结构模式。Redis 是内存数据结构服务器,采用键值模型存储多种数据类型(字符串、列表等),支持持久化与复杂操作;Memcached 是纯内存键值缓存,仅支持字符串且无持久化;MongoDB 是磁盘型文档数据库,以 BSON 格式存储结构化数据,支持类 SQL 查询。三者均脱离 SQL 范式,但数据存储位置与结构灵活性存在显著差异:Redis/Memcached 数据主要驻留内存(其中 Memcached 无持久化),而 MongoDB 数据持久化于磁盘;Memcached 仅支持简单键值,Redis 支持多种数据结构。
SQL Server的安装
develop版全功能不可以用于生产环境
express功能受限,免费
1.安装选择下载介质
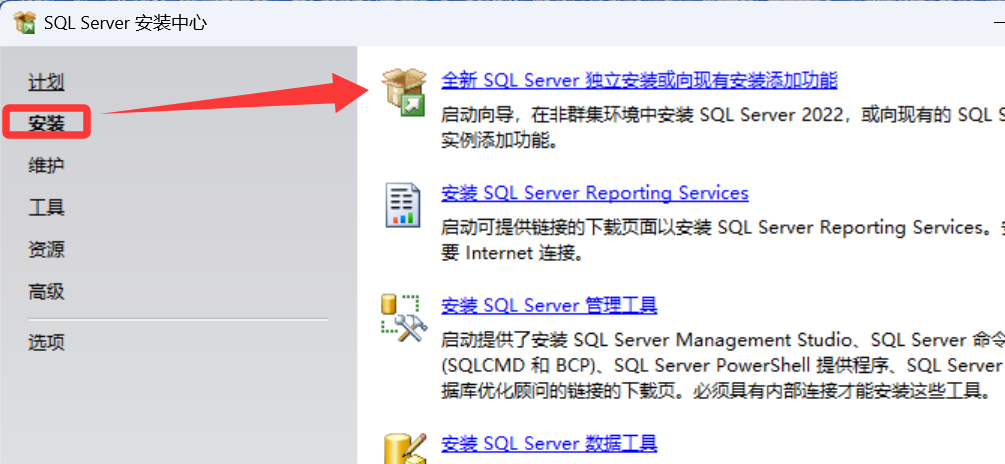
2.取消勾选Azure云提供的一些服务和支持
.png)
3.选择实例功能
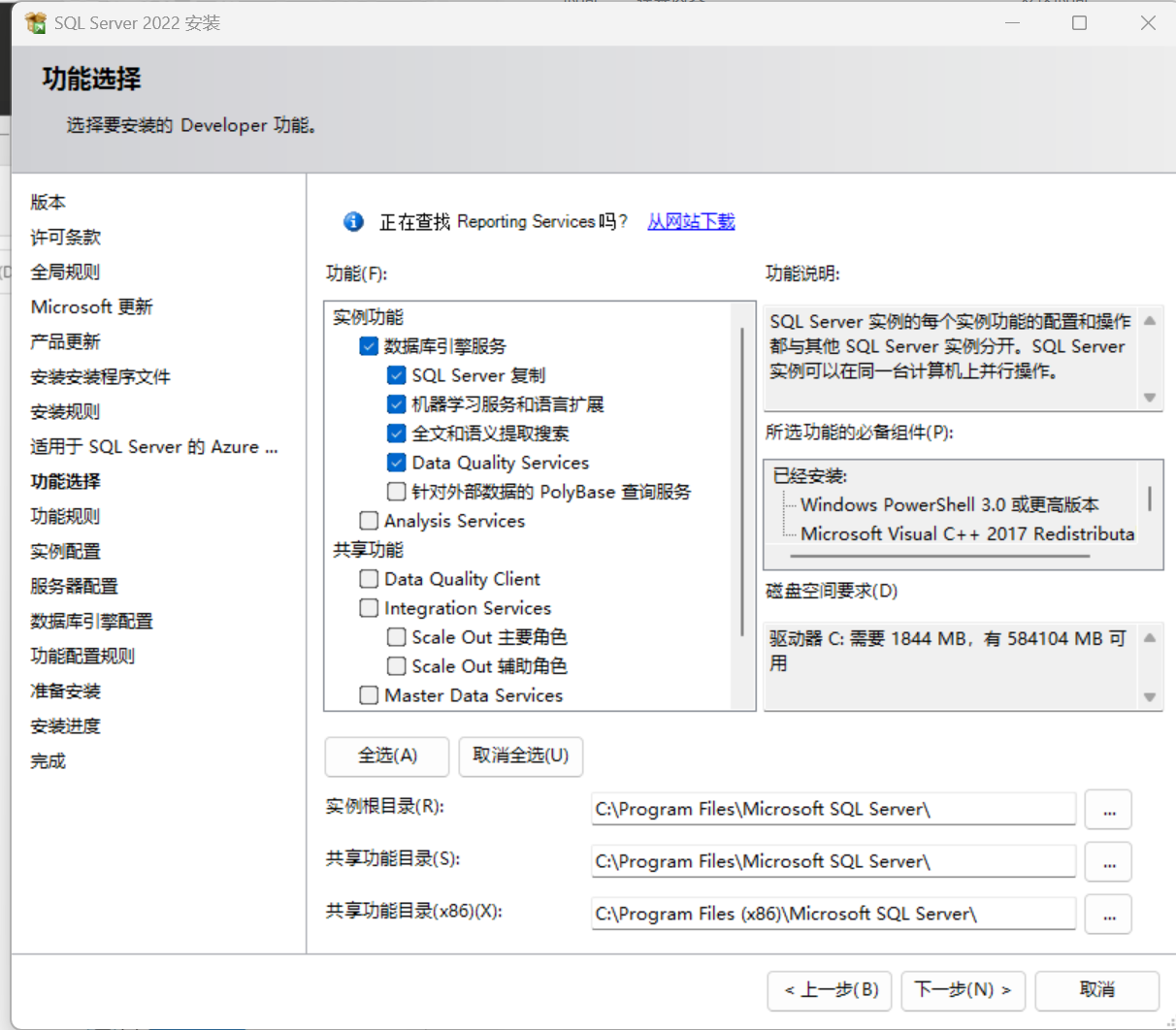
4.实例配置-默认实例
5.browser勾选自动,主要是远程连接数据库时起作用
.png)
设置密码
6.设置密码,可以忘记密码时还能使用Windows账号来登录
.png)
7.安装完成打开sql配置管理器,启用tcp/ip来允许远程连接
.png)
8.重启电脑。如果防火墙开启,则需要添加三个程序
.png)
.png)
.png)
9.添加完成后注意勾选专用和公用网络
配置SSMS
SQL Server Management Studio
连接对话框:在“工具”>“选项”>“环境”>“连接”中切换新的和经典连接对话框体验
.png)
SQL身份验证是安装时的系统管理员,账号sa
加密选项:使用Windows用户认证,要么勾选信任证书,要么取消强制加密
右键数据库属性可修改相关设置
.png)
修改密码
右键属性
.png)
2.基本使用方法
登录数据库
如果启动了sql broswer服务,在服务器名称选择浏览更多查看
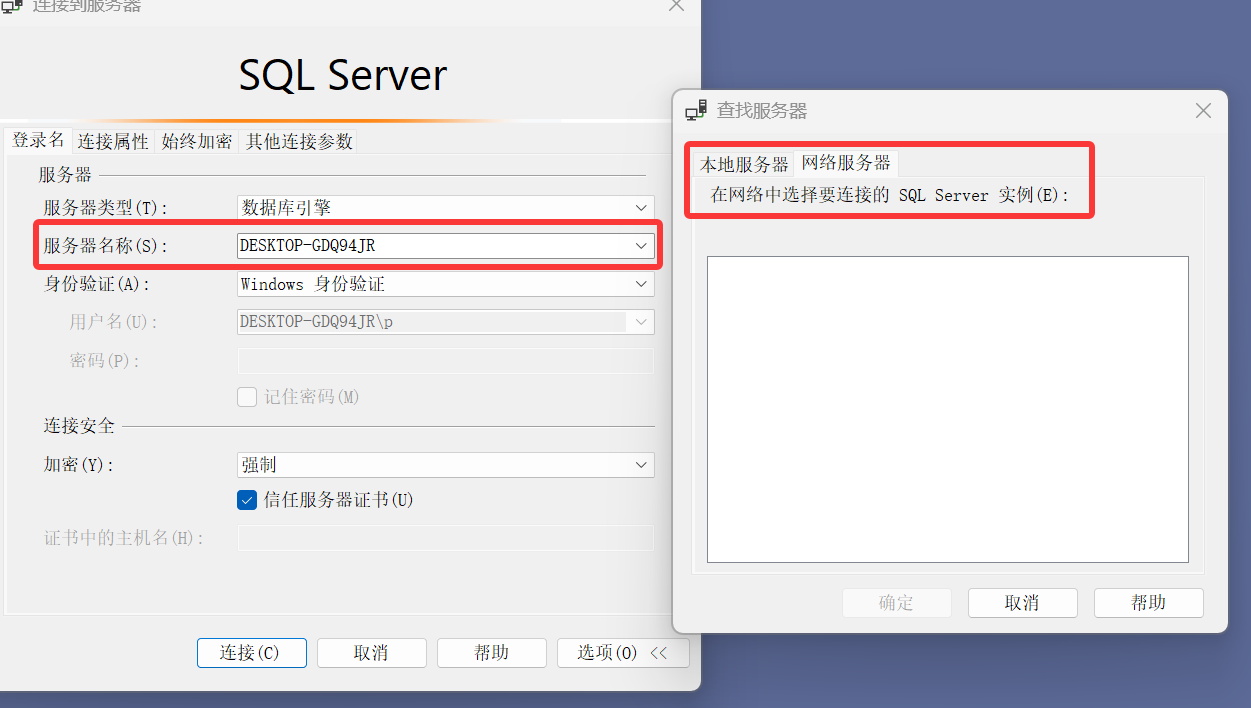
右键数据库服务器处可以断开连接
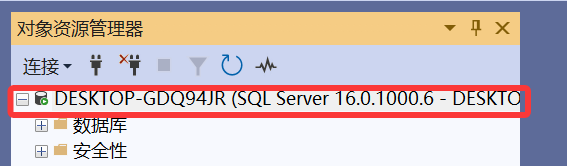
重新连接
.png)
如果是express版本还需要在实例名后添加后缀
修改字体大小
工具-选项-字体和颜色,修改在新建查询时窗口的字体和大小
create database 新建数据库
新建查询,test表示操作的对象(此时还没建test库)
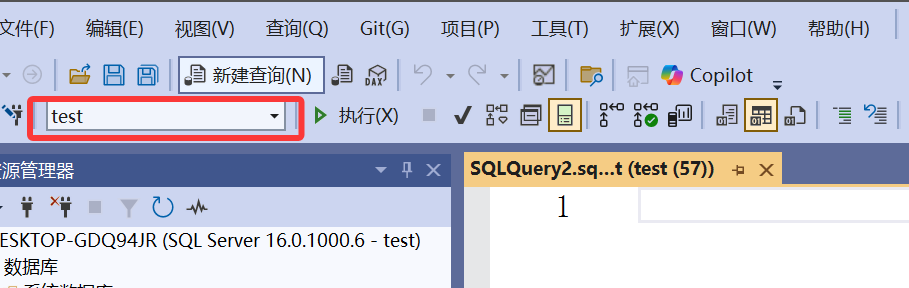
create database 数据库名在SQL Server中,建议对于对象的名称使用中括号, create database [数据库名] , 这样即便数据库名是有意义的保留字段,也一样可以建立操作。
在mysql中是用 ` 来包裹特殊字符。
linux中数据库语句依赖分号 ; 作为显式结束符,在Windows中不需要。
执行SQL语句。
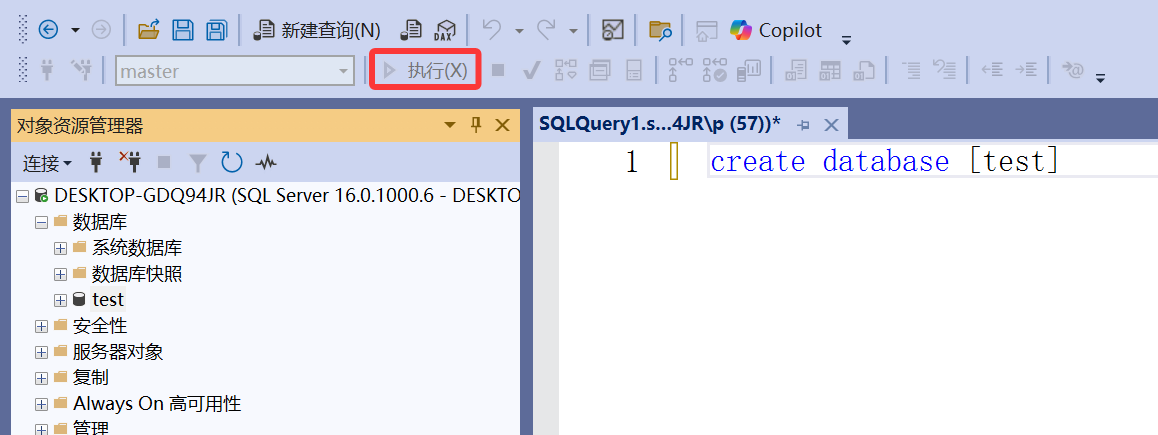
执行后右键刷新数据库或者数据库服务器。
新建登录用户
建立登录名
在图形化界面中操作,找到安全性,右键登录名。
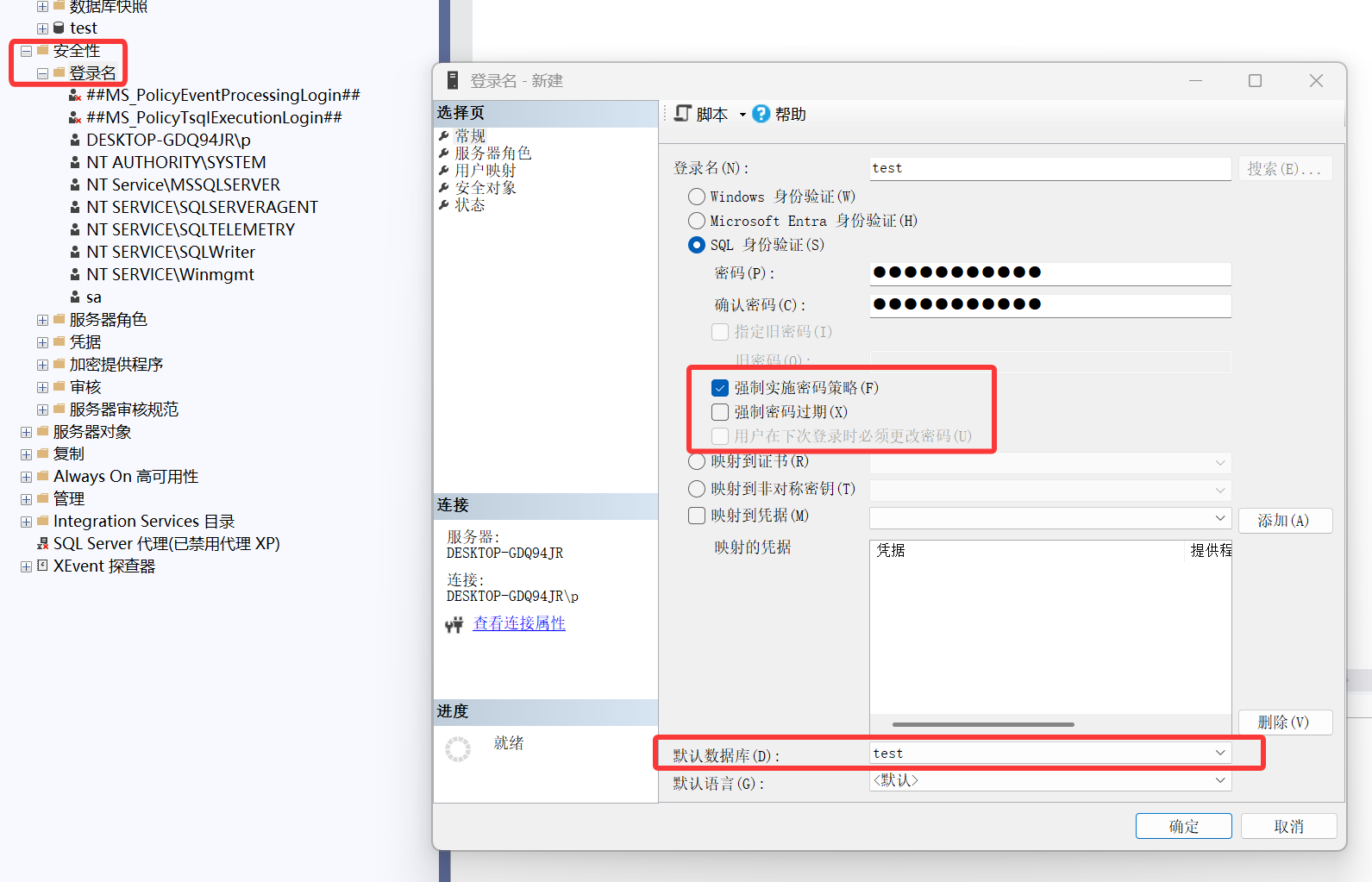
选择默认数据库:用户登录时默认操作的对象。
建立用户
先进入到相应的数据库,比如刚才创建的test,再去右键安全性-用户。
填写用户名、登录名、默认架构。
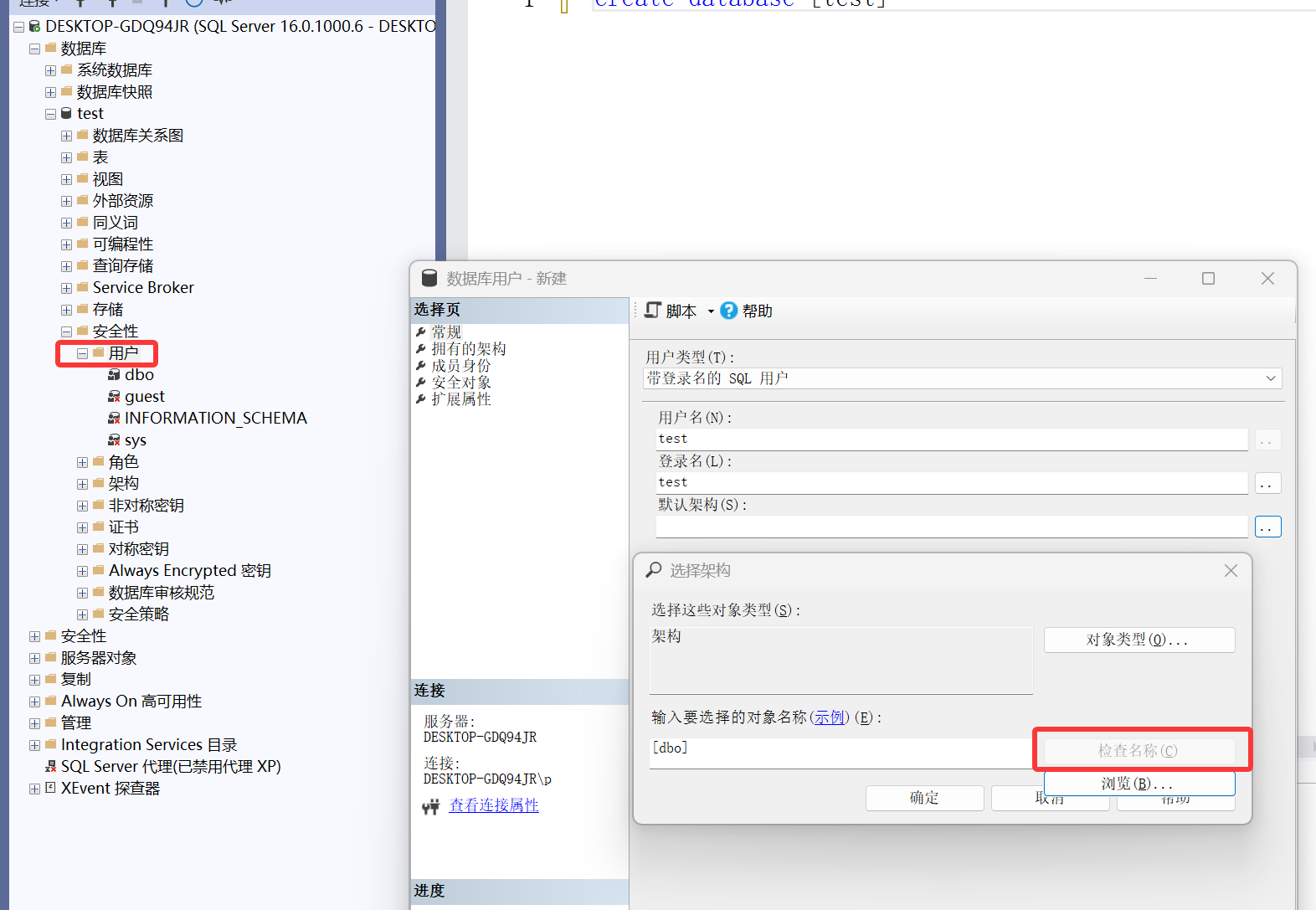
这里可使用检查名称检查登录名和默认架构是否输入错误。
dbo是每个数据库的内置管理员用户,代表数据库所有者。
dbo同时是一个预定义架构,用于组织数据库对象。
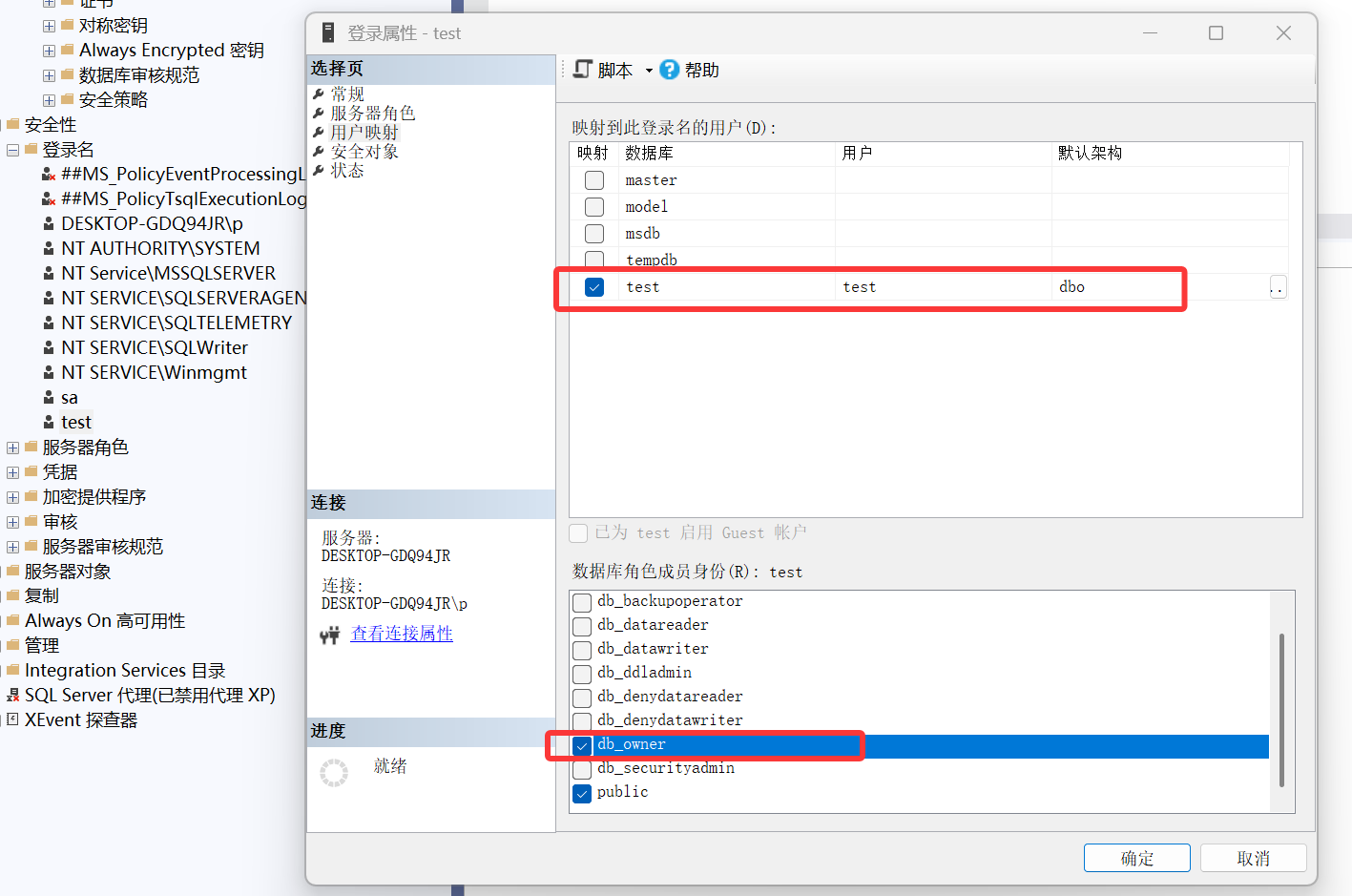
回到开始创建的登录名,属性-用户映射:
数据库test下的用户test,打勾给予其数据库拥有者的权限。
对数据库里面的内容有操作权限,但是无法删除数据库本身。
create table 新建表
CREATE TABLE [数据库名].[表名] (
[字段名1] [数据类型],
[字段名2] [数据类型]
)
省略数据库名,默认在当前连接的数据库中创建表
create table [students]
(
[Id] bigint not null
)
不可省略的部分
1.表名
2.字段名与数据类型
3.括号与逗号NOT NULL约束 作用:强制要求字段必须包含有效值,禁止插入 NULL(空值),此处默认是null允许空值。
BIGINT是数据库中的整数类型,用于存储超大范围的整数值。
图形化界面新建表
图形化界面下右键数据库-库名-表-新建表。
列名
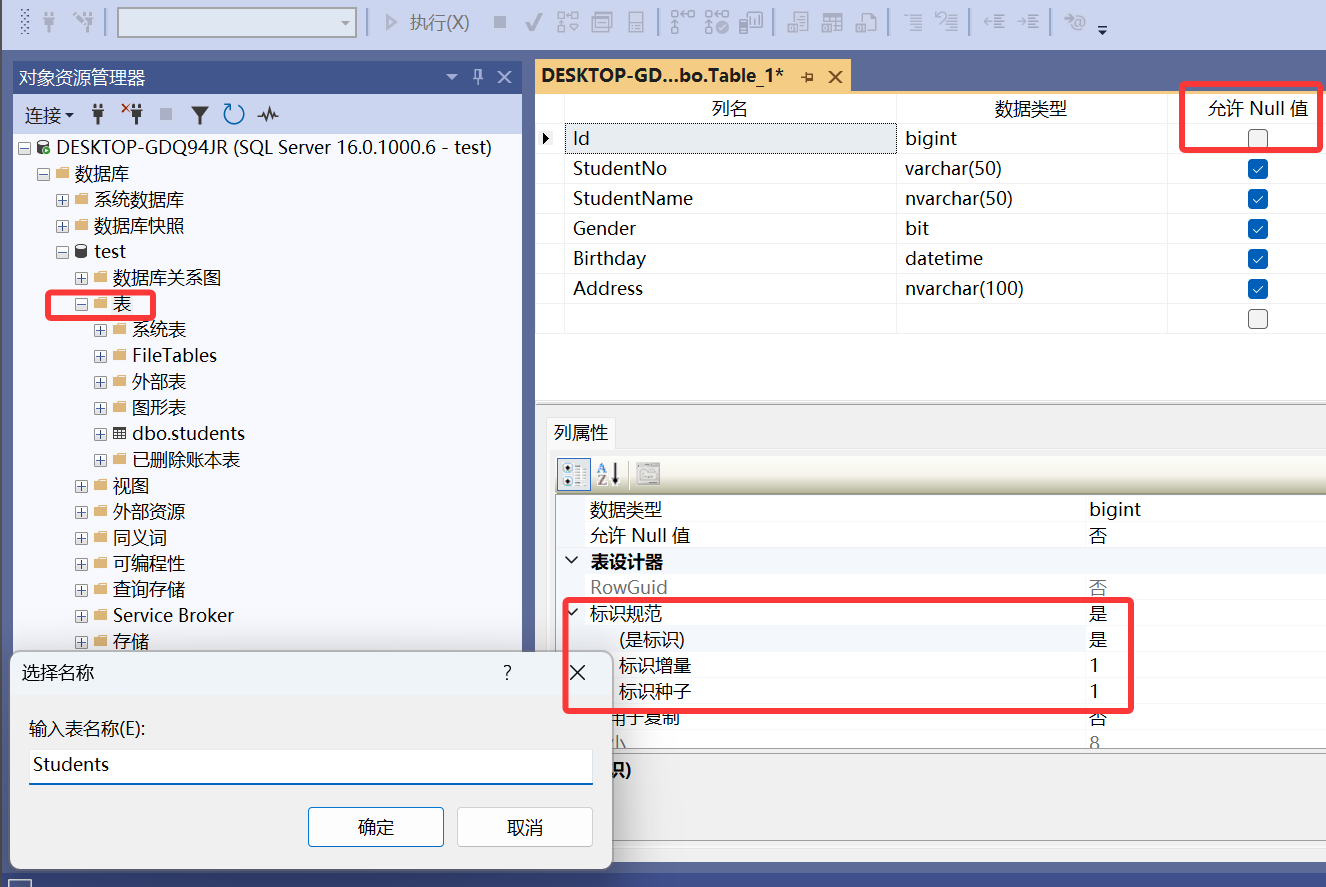
在 SQL Server 中,表头即指表的列名(字段名),用于标识每一列数据的含义(如 StudentID、Name)。
varchar 可变字符长度 仅支持单字节字符(英文、数字等)。
nvarchar 支持多语言字符(中文、日文、Emoji 等)每字符 2 字节(所有字符)。
bit 只有0 1,来表示true 和false。
日期+时间 → DATETIME 固定赋值格式YYYY-MM-DD HH:MM:SS(例如 2025-08-09 14:30:00)。
仅日期 → DATE; date的存在意义是比较节省空间。
对于第一列的列名 id,修改其标识规范。表示自建的这个id列的含义是每一行数据的唯一标识,从1开始增加。
右键此标签页保存,或者退出时提示保存。
图形化界面编辑
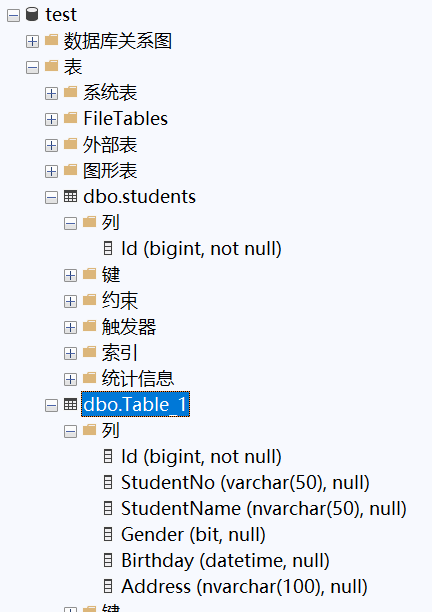
右键表选择编辑前200行开始编辑。
编辑时显示感叹号表示未提交到数据库,当进入下一行的编辑时自动提交。
由于设置了标识规范,id列自动自增无法编辑。
3.基本SQL语句
select
select
[Id],
[StudentName]
from Table_1多个列名之间用逗号隔开。
as的用法
select
[Id] as 标识,
[StudentNo] as学号,
[StudentName] as姓名,
[Gender] as 性别,
[Address] as 地址,
from [Students]用as指代别名,只是查询的结果上列名换了名字
where 条件子句
等值查询 (=)
SELECT * FROM t WHERE id = 1
in 多值匹配
select
[Id],
[StudentName]
from Table_1
where [Id] = 2
---------------------或者用in列举多个列中的值,IN列表中的值必须与目标列的数据类型匹配。
where [Id] in (1,2)
---------------------等价于 WHERE [Id] = 1 OR [Id] = 2,详见条件查询章节
---------------------若列是字符串(如 Department),则需加引号:IN ('IT', 'HR')。进阶用法:子查询返回的结果集将作为
IN的匹配值列表
SELECT [Id], [StudentName]
FROM Table_1
WHERE [Id] IN (SELECT StudentId FROM Table_2 WHERE Score > 90)like 模糊查询 %
select
[Id],
[StudentName]
from Table_1
where [StudentNo] like '%345%'
这里%就代表零个或多个任意字符,意思就是不知道学号,但是学号中间是包括有345的case 值匹配
针对列结合when做等值匹配
select
[Id],
[StudentNo] ,
[StudentName] ,
case [Gender]
when 1 then '男'
when 2 then '女' ---查询结果将数字编码的性别值(1 或 2)转换为中文描述('男' 或 '女')。
end as 性别,
[Birthday] ,
[PhoneNo] ,
[ProvinceId] ,
[CityId] ,
[DistrictId],
[StreetId],
[Address]
from [Students]END是 SQL 标准规定的语法闭合符,用于明确CASE表达式的边界。
drop 删除表
drop table [dbo].[students]删除表 dbo.students,这里dbo是默认的,可加可不加,只是表示该表是dbo结构的。
DROP DATABASE 库名
drop table if exist [dbo].[students]
判断是否存在主要是防止删除时报错,更主要的用途:创建
CREATE TABLE IF NOT EXISTS [dbo].[students] (id INT)
CREATE DATABASE IF NOT EXISTS MyDBcreate 新建表
identity
对于先前在图形界面中将列名作为标识符,sql语句实现使用identity(初始,步长)
MySQL 和 SQL Server 每个表仅允许一个标识列,且必须为数值类型并关联键约束。
SET IDENTITY_INSERT [dbo].[Areas] OFF控制是否允许手动插入标识列的值,OFF表示关闭手动插入模式,恢复自增特性。
-- 创建名为 'Students' 的表(位于dbo模式)
CREATE TABLE [dbo].[Students]
(
[Id] BIGINT IDENTITY(1, 1) NOT NULL, -- 🔑 主键:自增ID(从1开始每次+1)
[StudentNo] VARCHAR(50) NULL, -- 📝 学号(非必填,字母+数字)
[StudentName] NVARCHAR(50) NULL, -- 👤 姓名(支持中文,例:张三)
[Gender] BIT NOT NULL, -- ♂️ 性别(布尔值:0=女,1=男)
[Birthday] DATETIME NULL, -- 🎂 出生日期(格式:YYYY-MM-DD HH:MM:SS)
[PhoneNo] VARCHAR(100) NULL, -- 📱 电话(纯数字,可存国际号)
[ProvinceId] BIGINT NULL, -- 🗺️ 省级行政区ID(外键预留)
[CityId] BIGINT NULL, -- 🏙️ 市级ID(外键预留)
[DistrictId] BIGINT NULL, -- 🏘️ 区/县级ID(外键预留)
[StreetId] BIGINT NULL, -- 🏡 街道ID(外键预留)
[Address] NVARCHAR(200) NULL, -- 🏠 详细地址(支持中文长文本)
-- ⭐ 核心主键约束定义(关键!)
CONSTRAINT [pk_student_id] -- 🏷️ 命名约束(便于后续管理)
PRIMARY KEY CLUSTERED -- 🔍 聚集索引(物理存储按ID升序排列)
([Id] ASC) -- ↑ 提升按ID查询速度50~100倍
)CONSTRAINT主键约束
[Id]列已被定义为表的主键,为何还需主键约束?
IDENTITY仅实现自增,不保证唯一性或数据完整性
唯一性:确保 [Id]列的每行值不重复(如插入重复值会报错)。
非空性:主键列 [Id]自动强制为 NOT NULL(即使未显式声明)。
constraint [pk_student_id]:定义一个约束,并给这个约束命名为pk_student_id。约束名称在数据库中必须唯一。
primary key:表示这是一个主键约束。主键约束的作用是确保该列(或列组合)的值唯一且不为空(NOT NULL)。这里的主键是Id字段。
clustered:表示这个主键索引是聚集索引(clustered index)。在SQL Server中,聚集索引决定了表中数据的物理存储顺序。每个表只能有一个聚集索引,因为数据行本身只能按一种顺序存储。
([Id] asc):指定索引的键为Id列,并且按升序(asc)排列。升序是默认的,所以也可以省略asc。降序为desc。
聚集索引的优势:由于聚集索引决定了物理存储顺序,因此按主键(Id)进行范围查询(如WHERE Id BETWEEN 100 AND 200)或排序(如ORDER BY Id)会非常高效,因为数据在磁盘上是按顺序存储的。id : 1 2 3 4 .......
default
当插入新记录时,若未显式为某列提供值,数据库自动使用默认值填充该列。
CREATE TABLE orders (
order_date DATETIME DEFAULT CURRENT_TIMESTAMP -- 插入时自动填充当前时间
)insert 插入
包含 INTO关键字,支持显式指定列名(推荐写法)。
INSERT INTO 表名 (列1, 列2) VALUES (值1, 值2);省略 INTO关键字,则必须省略列名,只能按表定义顺序插入所有列的值
INSERT 表名 VALUES (值1, 值2); -- 需为所有列赋值插入字符类型需要单引号,如果插入10列没有对应的10个值就会报错。留空应该使用null。
insert into [dbo].[Students]
([StudentNo], [StudentName], [Gender], [Birthday], [PhoneNo], [ProvinceId], [CityId], [DistrictId], [StreetId], [Address])
values
('19041315','某某某同学',1,'2001-3-29','18976264312',1,2,3,null,'某小区')delete 删除表中数据
DELETE:仅删除表中的数据行,不破坏表结构
DROP:删除整个数据库对象(如表、索引、视图)
delete from[dbo].[Students]
where [Id] in (2, 3)3.1 update更新和join连接
建立一个测试用的表。
-- 🗑️ 如果存在名为 [Areas] 的表则立即删除
-- 💡 说明:避免后续建表时因表名冲突报错(`IF EXISTS` 是 SQL Server 2016+ 语法)
DROP TABLE IF EXISTS [Areas]
GO -- ⚡ 批处理结束并执行(确保表已物理删除)
-- 🏗️ 创建区域表 [Areas]
CREATE TABLE [Areas]
(
[Id] BIGINT NOT NULL, -- 🔑 区域唯一ID(主键)
[ParentId] BIGINT NOT NULL, -- 🧩 父区域ID(用于树形结构,0表示根节点)
[AreaName] NVARCHAR(50) NOT NULL, -- 🌍 区域全名(支持中文如"北京市")
[ShortName] NVARCHAR(50) NULL, -- 🔖 区域简称(可空,如"京")
-- 🔒 主键约束定义(关键!)
CONSTRAINT [pk_area_id] -- 🏷️ 命名约束(便于后续管理)
PRIMARY KEY CLUSTERED -- 💾 聚集索引(按Id物理排序存储)
([Id] ASC) -- 📈 升序排列(优化范围查询)
)
GO -- ⚡ 批处理结束并执行(表结构正式生效)GO不是 SQL 语句,而是客户端工具命令(如 SSMS、sqlcmd),用于分隔批处理指令。
update
UPDATE 表名
SET 列1 = 值1, 列2 = 值2, ...
WHERE 条件不加where限定行时,操作所有行。
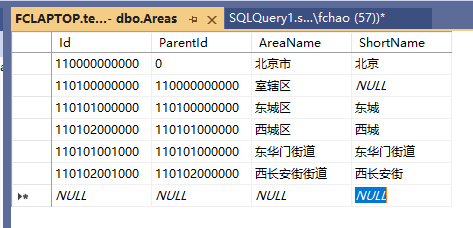
修改之前建立的student学生表里面的地区信息。
update [dbo].[Students] set
[ProvinceId] = 10000000000,
[CityId] = 11010000000,
[DistrictId] = 110101000000,
[StreetId] = 110101001000
where [id] = xxxxupdate修改的结果:
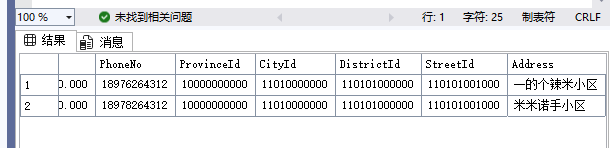
需要将areas表的地区内容连接到先前的student表以在此处显示地名而不是直接的区位编号。
join、as、on
join通过关联字段的值匹配,将分散在多个表的字段横向拼接为完整业务实体。
下面的例子可以看到同时select两张表
一旦表通过 JOIN被关联,SELECT子句即可自由选择:
- 主表(如 stu) 的任何列(如 stu.Id);
- 关联表(如 p, c, d, s) 的任何列(如 p.AreaName),p、c、d、s是关联表的别名。
Id是区域表的唯一标识(主键),所以使用 Id列进行连接。
匹配逻辑:
•若 A.id=1且 B.id=1→ 匹配成功,保留组合;
•若 A.id=1但 B.id=2→ 匹配失败,丢弃组合。
INNER JOIN仅保留双方匹配的行
LEFT JOIN保留左表所有行 + 右表匹配行
RIGHT JOIN保留右表所有行 + 左表匹配行
FULL JOIN保留左右表所有行
执行流程:
1.遍历学生表(stu)每一行:
•读取学生数据(如 Id=1, ProvinceId=42, CityId=101)。
2.动态匹配行政区划:
•省级匹配:用 ProvinceId=42在 Areas表(别名 p)中查找 id=42的行 → 返回省名(如 "广东省")。
•市级匹配:用 CityId=101在 Areas表(别名 c)中查找 id=101的行 → 返回市名(如 "深圳市")。
•区级/街道匹配:同理(若 DistrictId或 StreetId为 NULL,则对应字段为 NULL)。
3.直接输出组合结果:Students 表:
Areas 表(Id 唯一):
查询结果:
-- 🎯 查询学生信息及其所属省、市、区、街道的名称
SELECT
stu.[Id], -- 👤 学生唯一标识
stu.[StudentNo], -- 📝 学号
stu.[StudentName], -- 👤 姓名
stu.[ProvinceId], -- 🏞️ 省级ID(外键)
p.[AreaName] AS 省, -- 🌍 省级名称(通过JOIN关联)
stu.[CityId], -- 🏙️ 市级ID
c.[AreaName] AS 市, -- 🏢 市级名称
stu.[DistrictId], -- 🏘️ 区/县级ID
d.[AreaName] AS 区, -- 🏡 区/县名称
stu.[StreetId], -- 🛣️ 街道ID
s.[AreaName] AS 街道, -- 🏘️ 街道名称
stu.[Address] -- 📍 详细地址(门牌号等)
FROM
[Students] AS stu -- 主表:学生信息表【别名stu】
-- 🔗 连接省级名称(左连接:确保无省份信息的学生仍被查询)
LEFT JOIN [Areas] AS p -- 省级区域表【别名p】
ON p.[Id] = stu.[ProvinceId] -- 关联条件:学生.省ID = 区域表.ID
-- 🔗 连接市级名称(左连接:确保无城市信息的学生保留)
LEFT JOIN [Areas] AS c -- 市级区域表【别名c】
ON c.[Id] = stu.[CityId]
-- 🔗 连接区级名称(左连接)
LEFT JOIN [Areas] AS d -- 区/县级区域表【别名d】
ON d.[Id] = stu.[DistrictId]
-- 🔗 连接街道名称(左连接)
LEFT JOIN [Areas] AS s -- 街道表【别名s】
ON s.[Id] = stu.[StreetId];
【总结】
LEFT JOIN [关联表] AS [别名] ON 主表.[关联字段] = 关联表.[关联字段]LEFT JOIN = LEFT OUTER JOIN(功能完全一致)as都是可以省略的,可直接换成空格代替。但是可读性会变差。
这里 xx = xx只是表示关联,不是赋值!交换等号的先后顺序对结果无影响。
查询的结果:

join的嵌套
截图中的写法和之前最本质的区别是:
p.[Id] = stu.[ProvinceId]
平行连接:逻辑上来说ProvinceId就是省份的区位编码,用这个区位编码直接到另一张表查询省份的名字。
c.[Id] = d.[ParentId]
图片中的查询: 通过 ParentId字段,从某个(省→市→区县→街道)层级,查找它的上级下级地区是什么。
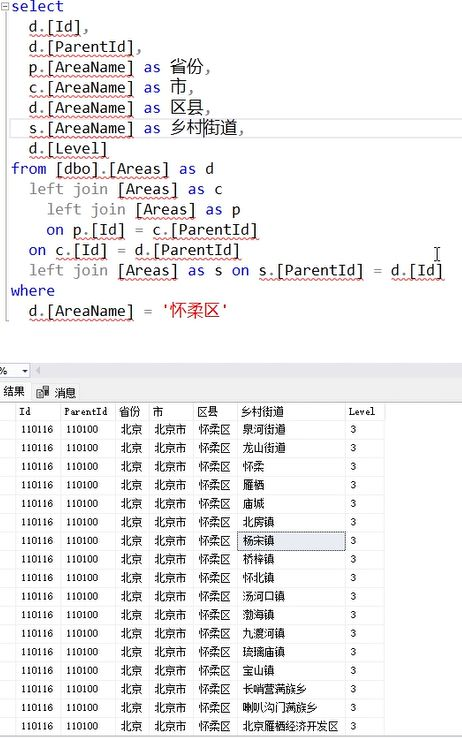
Level 是层级标识字段:通过数值表示行政级别深度。
【图中“嵌套”的写法和以下写法一致】
FROM [Areas] AS d -- 🌟 核心:从「区县级」记录开始(怀柔区)
LEFT JOIN [Areas] AS c ON c.[Id] = d.[ParentId] -- ← 怀柔区的父id来查找怀柔区的父级(市级)
LEFT JOIN [Areas] AS p ON p.[Id] = c.[ParentId] -- ← 查找市级的父级(省级)
LEFT JOIN [Areas] AS s ON s.[ParentId] = d.[Id] -- → 查找怀柔区的子级(街道)
1.写之前搞清楚这个一个列。它的逻辑(比如省市镇)的上下级关系。
2.确定查询锚点(FROM 主表),已知什么,需查询谁的上下级信息。
FROM [dbo].[Areas] AS d -- 以区县级(怀柔区)为基准
3.向上关联(找上级)
(1)关联市级(c表)
LEFT JOIN [Areas] AS c ON c.[Id] = d.[ParentId]
-- 关键:d.[ParentId] 存储其上级(市)的ID
- 判断逻辑:
- 区县表(d)的 ParentId必然指向其直属上级(市级)的 Id
- 因此用 d.ParentId = c.Id
(2)关联省级(p表)
LEFT JOIN [Areas] AS p ON p.[Id] = c.[ParentId]
-- 关键:c.[ParentId] 存储其上级(省)的ID
- 判断逻辑:
- 市级表(c)的 ParentId指向其上级(省级)的 Id
- 因此用 c.ParentId = p.Id
4. 向下关联(找下级)
LEFT JOIN [Areas] AS s ON s.[ParentId] = d.[Id]
-- 关键:s.[ParentId] 存储其上级(区县)的ID
- 判断逻辑:
- 乡镇表(s)的 ParentId指向其上级(区县级)的 Id
- 怀柔区(d)的 Id是各乡镇的父级ID
- 因此用 s.ParentId = d.Id
4.条件查询
where条件数值比较
select * from [Areas]
where
[Id]<1000000
不等于用<>或者!=来表示
SELECT * FROM users WHERE age != 25not and or 多个条件的连接
也叫做逻辑操作符
select * from [Areas]
where
[Level]< 4 and [AreaName]= '北京'
--------------
[Level]< 4 and [AreaName] like '%北京%'
--------------
[Level]<4 and [AreaName] like '%北京%'
or [Level] = 4 and [AreaName] like '%天津%'
同时使用and和or。and的优先级较高,会认为是在两个and中间去or。
为了可读性建议使用括号。
([Level]<4 and [AreaName] like '%北京%' )
or ([Level] = 4 and [AreaName] like '%天津%')not逻辑取反
SELECT * FROM orders WHERE status NOT IN ('completed', 'cancelled')
SELECT * FROM products WHERE name NOT LIKE '%discount%'
SELECT * FROM employees WHERE salary NOT BETWEEN 5000 AND 10000declare变量
-- 1️⃣ 声明变量(指定名称和数据类型)
DECLARE @变量名 数据类型 [= 默认值];
DECLARE @areaname nvarchar(50);
-- 2️⃣ 变量赋值(两种方式)
SET @变量名 = 值; -- 标准赋值(推荐)
SELECT @变量名 = 值; -- 从查询结果赋值
DECLARE @num1 INT = 5, @num2 INT = 10, @sum INT;
SET @sum = @num1 + @num2;
SELECT @sum AS Result; -- 输出 15
......
where
p.[Level] = 1 and(c.[AreaName] like @areaname or d.[AreaName] like @areaname or s.[AreaName] like @areaname) and (not p.[Id]=110000)
这里and (not)的用法可以换成不等于 p.[Id]!=110000order排序
SELECT 列1, 列2 FROM 表名 ORDER BY 排序列 [ASC|DESC]
- 可以order by [as的别名],不一定是列名
- ASC:升序(默认,小→大)
- DESC:降序(大→小)补充
year
- Year()是一个 SQL 函数,专门用于从日期(DATE)或日期时间(DATETIME)类型的字段中提取年份值。
- 类似的还可以用month和day
WHERE class.[OrganName] = '信计1801'
AND Year(student.[Birthday]) = 2000 -- ✅ 提取生日年份并判断是否等于2000format
1. FORMAT(字段值, '格式模板')
'yyyy-MM-dd'是标准日期格式,截图中将格式模板表达为yyyy年M月d日
2. FORMAT(字段值, '格式模板' , '区域格式')
SELECT
FORMAT(1234.56, 'C', 'en-US') AS '美元格式', -- $1,234.56
FORMAT(1234.56, 'C', 'zh-CN') AS '人民币格式', -- ¥1,234.56
FORMAT(1234.56, 'C', 'de-DE') AS '欧元格式'; -- 1.234,56 €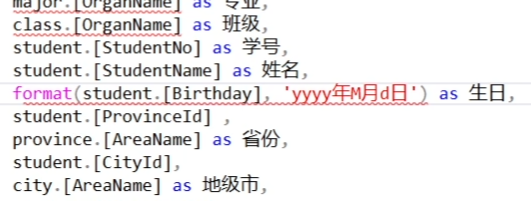
查询表空间
查询时使用的名称是数据库的逻辑名称
图形化查询方式:
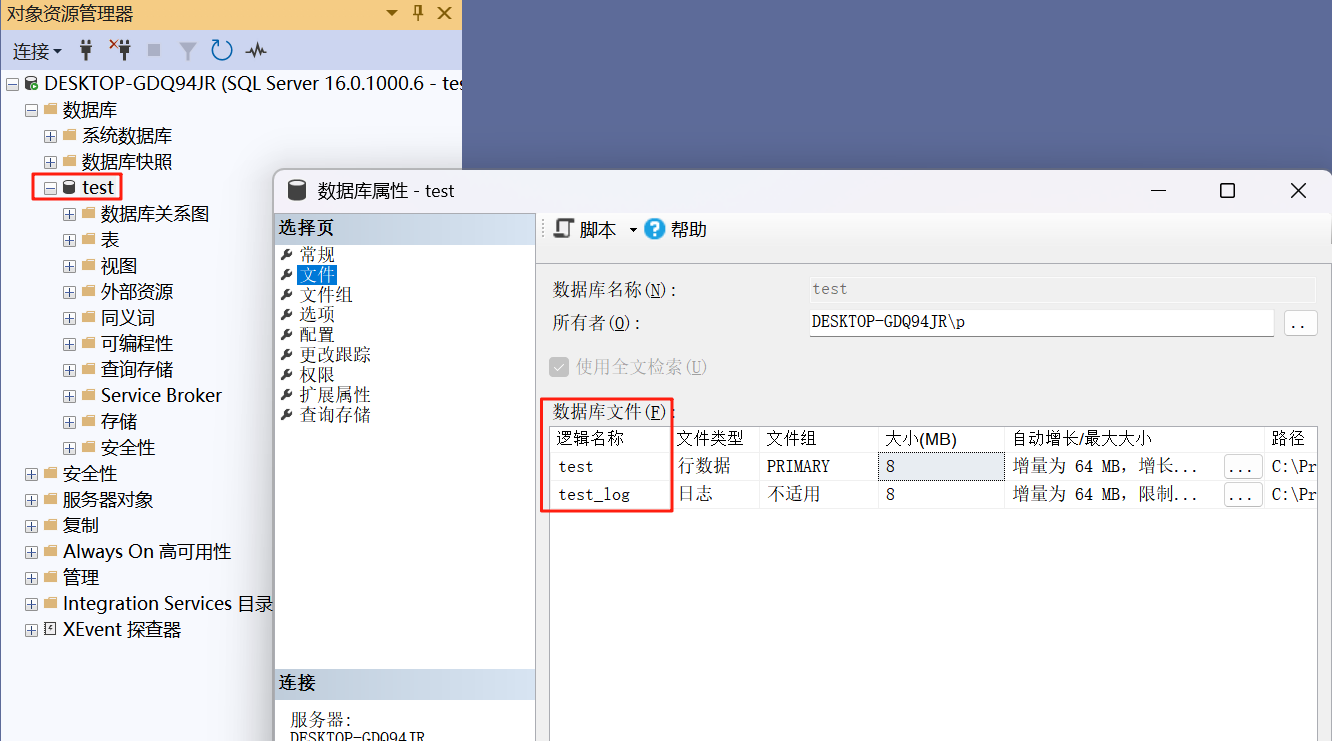
数据库查询方式
-- 查看当前数据库的文件信息
SELECT
name AS [逻辑名称],
physical_name AS [物理路径],
type_desc AS [文件类型]
FROM sys.database_files;SELECT
name AS [文件名称],
size/128.0 AS [总空间(MB)], -- 总页数 → MB
FILEPROPERTY(name, 'SpaceUsed')/128.0 AS [已用空间(MB)], -- 已用页数 → MB
(size - FILEPROPERTY(name, 'SpaceUsed'))/128.0 AS [剩余空间(MB)], -- 空闲页数 → MB
type_desc AS [文件类型] -- ROWS(数据文件)或 LOG(日志文件)
FROM sys.database_files; -- 当前数据库的文件信息视图
--1
SQL Server 中数据存储的基本单位是 页(Page),每页固定大小为 8 KB(8192 字节)。
1 MB = 1024 KB→ 1024 KB ÷ 8 KB/页 = 128 页
size / 128.0 将页数转换为 MB(例如 500 页 ÷ 128 = 3.90625 MB)。
--2
FILEPROPERTY()函数的作用
返回数据库文件的属性信息,需指定 文件名 和 属性名(如 'SpaceUsed')。
--3
sys.database_files
这是 SQL Server 提供的 系统目录视图,存储当前数据库中所有文件(数据文件、日志文件等)的元信息。
--4
type_desc
type_desc是 sys.database_files中的列,描述文件的类型分类