1.概念
RTF
RTF = 语音生成耗时 / 语音实际时长
语音生成耗时:模型从输入文本到生成完整音频所花费的时间(秒)
语音实际时长:生成音频的播放时长(秒)
假设你让模型生成一段 10 秒的音频:
如果生成耗时 5 秒 → RTF = 5 / 10 = 0.5
如果生成耗时 20 秒 → RTF = 20 / 10 = 2.0
RTF 值
<1 模型生成比实时播放快 → 可实时合成或在线 TTS
≈1 刚好实时生成
>1 模型生成比实际播放慢 → 不能实时使用,只适合离线生成
Token
token = 模型能理解和处理的“最小信息块”
广义上的 Token
在 AI(尤其是 NLP/生成模型)里:
Token = 模型处理的最小单位
可以是:
文本:单词、子词(subword)、字符
图像:patch/像素块(如 ViT、DALL·E token)
音频:声学单元或向量(如音素、mel frame token)
其他:任何可以离散化或嵌入的输入/输出单元
IndexTTS2 token
每个 token 不是文字,而是 语音特征单元:
音素、音高、时长、情感
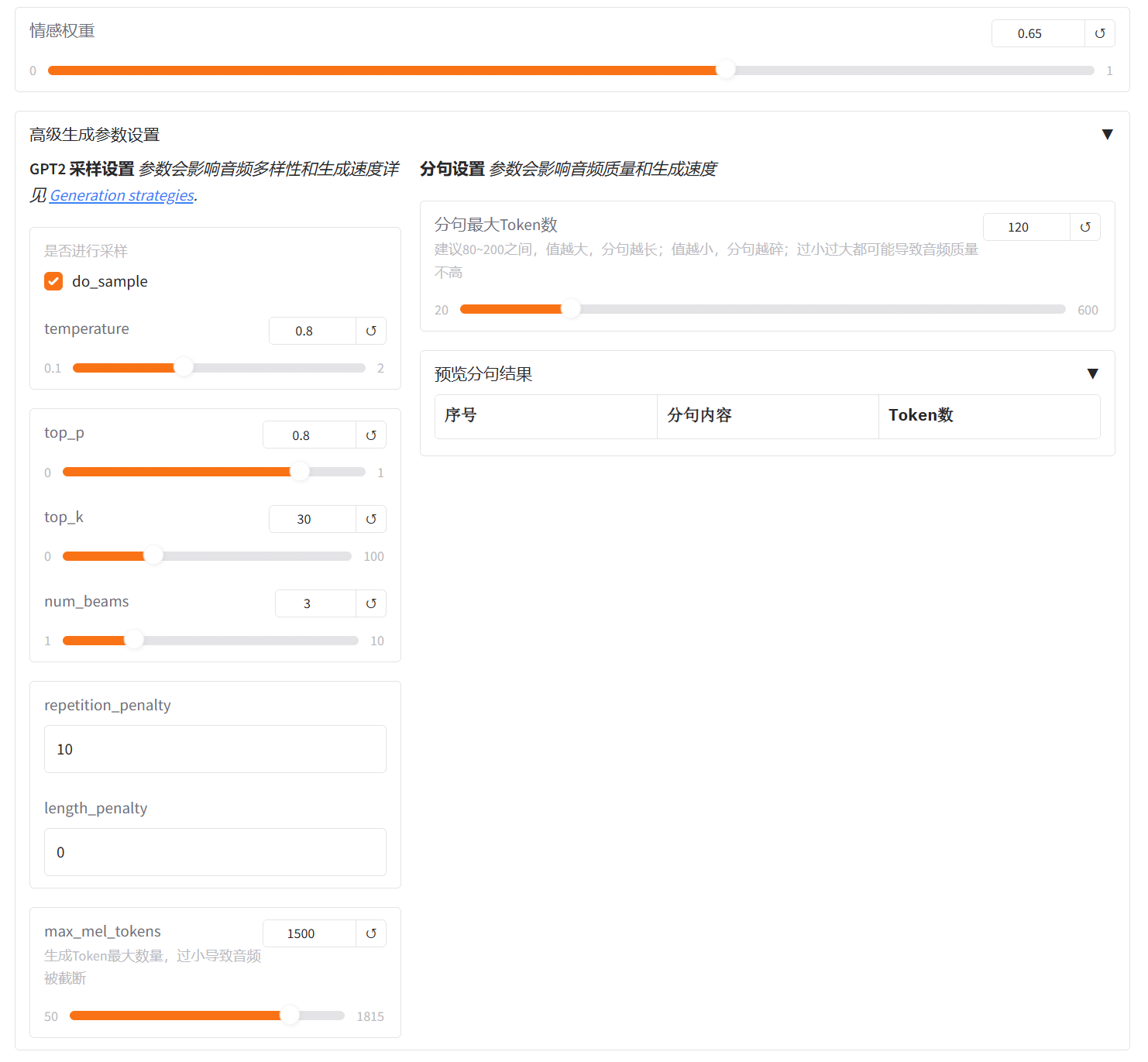
2.WebUI参数
1️⃣ do_sample
对音频情绪克隆的必选项,增加了生成语音的随机性和自然程度,避免了机械式的重复输出
2️⃣ temperature
控制语音生成时的随机程度,默认值0.8最自然
数值 越高 → 音调和韵律更有变化
数值 越低 → 音色和语速更稳定
TTS 建议:0.7~0.9 较合适,太高会导致韵律不自然
3️⃣ top_p
决定GPT2思考的上下文范围是保守还是开放,Top-p在大多数情况下表现更优,能使最终的语音情感更自然、更丰富
数值 越高 → 情绪、音调和韵律更富有变化,语气更贴近自然。适合角色配音、故事讲述、需要情感或变化的创意内容
数值 越低 → 音色和语速更稳定
TTS 建议:0.7~0.9 较合适,太高会导致韵律跑偏
4️⃣ top_k
控制语音生成的稳定性和可控性,决定GPT2思考时可选择的表达数量是谨慎还是多变
数值 越高 →数值越大它能从更多可能中选择语气更灵活表现更自然
数值 越低 →稳定性高,多次生成同一文本的结果非常相似。语调更保守、更平稳,缺乏情感变化,听起来可能比较机械。适合事实播报、新闻稿、需要高度一致性的场景
TTS 建议:建议40~60之间是最稳定的选择
5️⃣ num_beams
num_beams 就是指算法在每一步生成时要同时追踪和保留的候选序列的数量。决定GPT2在生成时思考的分支数量是单线还是多线。
数值 越高 →它会同时比较更多种可能的结果,语气更准确、但生成更慢。
显存充足可设置在4以上
6️⃣ repetition_penalty
repetition_penalty(重复惩罚)参数专门用于控制模型在生成序列时重复相同内容的倾向,可避免同一句生成中出现重复音素或拖长音。通常不需要调整。
它是一个大于或等于 1.0 的浮点数。
1.0 意味着没有惩罚。模型将按照其原始概率分布进行生成。
> 1.0 意味着施加惩罚。数值越大,惩罚越重。
如果生成的音频听起来卡顿或有回音: 增加 repetition_penalty 的值(例如从 1.0 增加到 1.1、1.2 或更高)。
如果生成的音频听起来失真、有噪音或语调怪异: 降低 repetition_penalty 的值。
7️⃣ length_penalty
length_penalty 是一个与 num_beams 配套使用的参数,用于控制生成音频的“完整性”和“长度”。1.0 是一个最合理的起始点。
前提: 确保
num_beams > 1。如果音频总是“话没说完就断了”: 增加
length_penalty(例如从 1.0 调到 1.5)。如果音频总是“拖泥带水”,结尾有怪异的长音或停顿: 降低
length_penalty(例如从 1.0 调到 0.8)。
8️⃣ max_mel_tokens
如果生成的音频所需的时间(Tokens) 超过了 max_mel_tokens 的限制,音频将在达到该限制时被“一刀切断”,非常突兀。
max_mel_tokens 主要是作为一种安全机制存在的
防止显存/内存溢出 (OOM Error)
防止无限循环
正常语速下保持默认1500,即能生成约5分钟左右的完整语音
9️⃣ 分句最大token数
模型不会一次性生成整篇长文的语音,而是会 把文本分句(或分段) 来处理。
分句最大token数就是用来限制单次生成的最大 token 数。建议80到200之间
值越大 → 分距越长、语气更连贯
值越小 → 分距越短、语气更碎
如果显存足够,建议在允许范围内设到较高值,比如180到200。这样模型能一口气说更长一句话,语气更自然,断句也更流畅
希望短句质量高:提高 num_beams
希望长句质量高:提高 分句最大token数
3.情感控制
3.1 情感参考音频
使用情感参考音频不受音色约束,对害怕语气还原较弱,可从1开始减少

3.2 情感向量控制
情感随机采样:当启用情感随机采样时,模型在参考音频的情感向量附近采样,每次生成都会稍微不同 → 语气细节、能量变化等略有差异
情感权重:控制了模型在合成时多大程度上依赖情感向量,也就是在生成语音时控制情绪强弱与表达幅度
最终情绪向量 = 基准语气 + (情感权重 × 参考情感向量)
4.ComfyUI

output_gain 输出增益:控制输出音频的音量大小
4.1 FP32 全精度 与 FP16 半精度
以浮点数 3.1415926 为例:
AI 模型(如 Stable Diffusion、IndexTTS、LLM)计算量极大,运行时需要存储大量权重和中间激活值。
FP32 → FP16 可以直接 减半显存占用
同时大多数现代 GPU(尤其是 RTX 系列)在 FP16 下还有 Tensor Core 加速,计算更快
4.2 情感向量控制
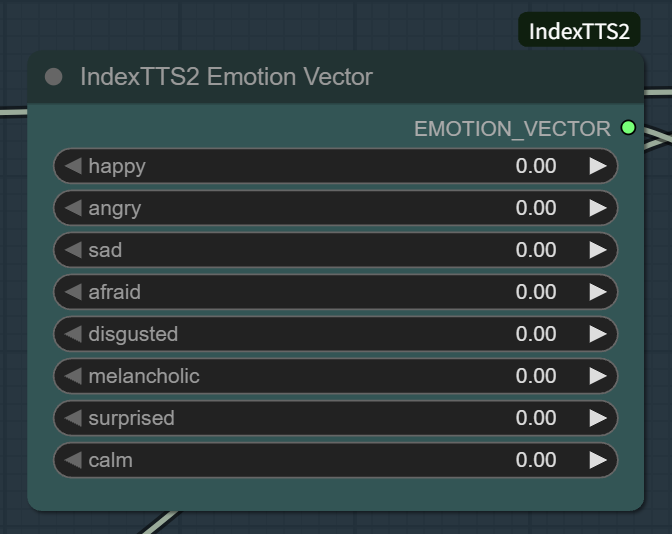
此处设置的总和不能超过1.5
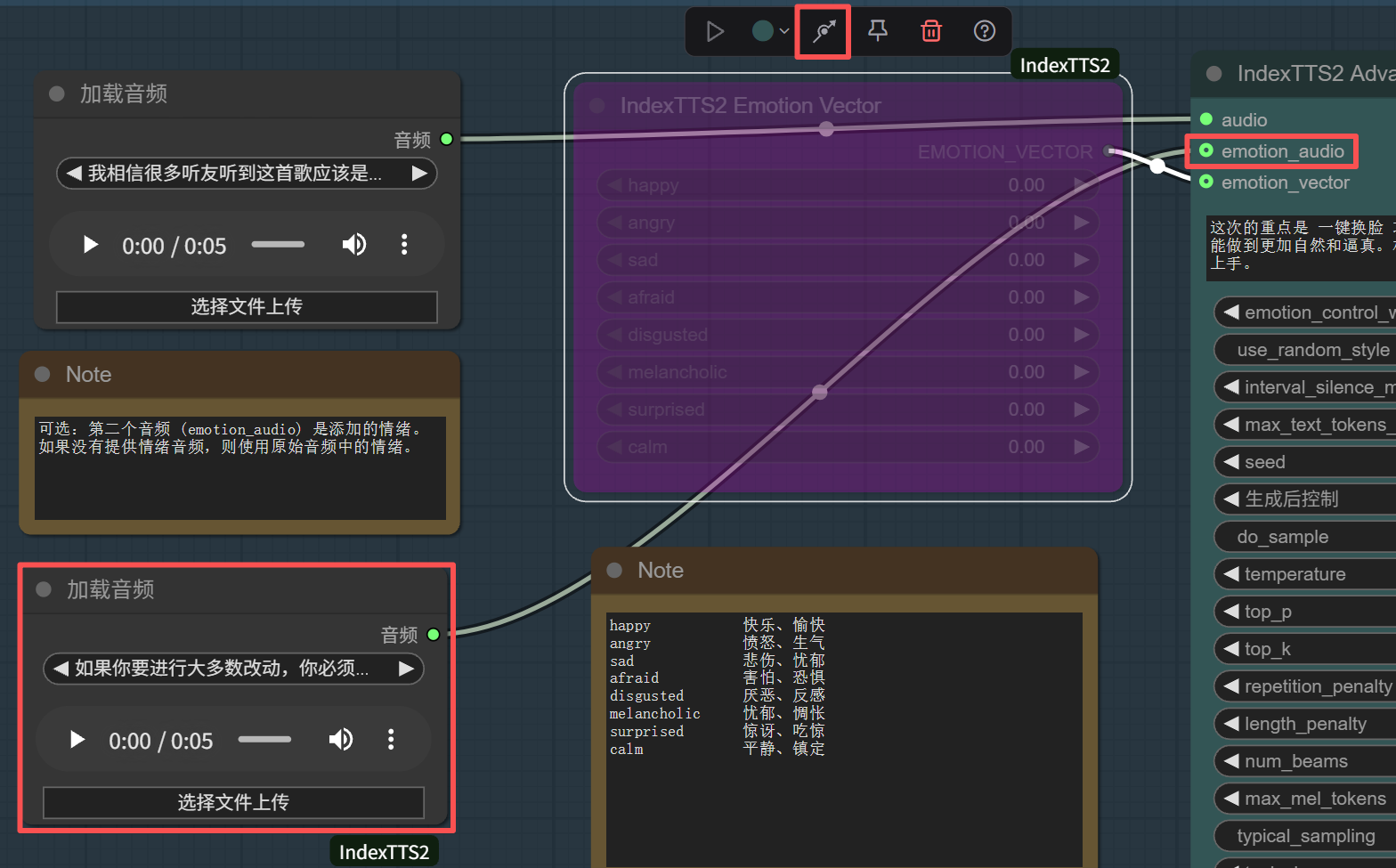
4.3 关闭情感向量控制,启用情感参考音频
通过节点上方的连接图标激活/关闭节点,使emotion_audio得到加载音频的输入
4.4 启用情感描述文本控制
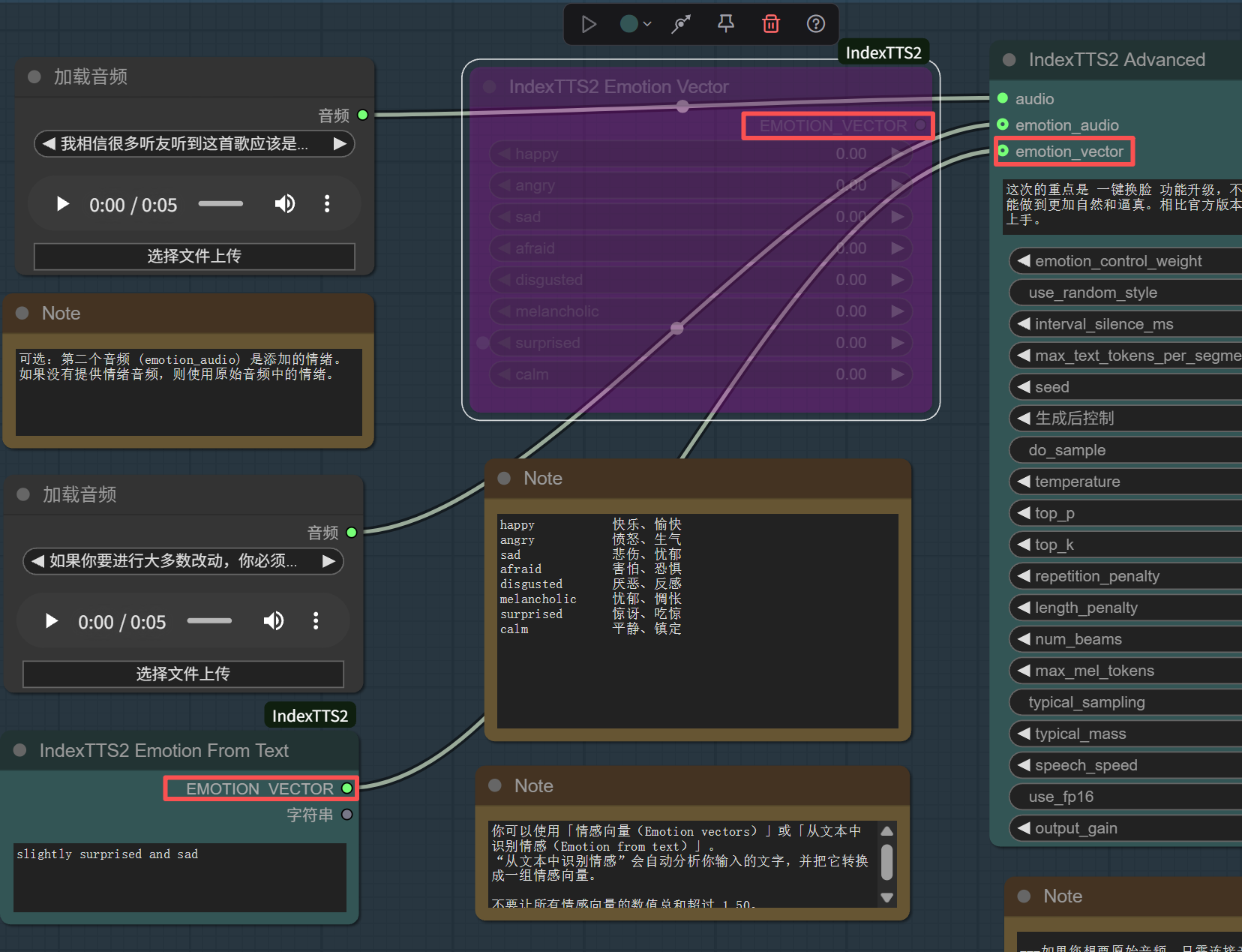
将情感描述文本控制节点的情感向量输出端与情感向量的输入端相连
补充:默认值
补充:自定义参考音频

要修改参考音频,直接将
工作路径\examples
下的音频进行替换并刷新webui网页