
2025真题:
某汽车博主为更好地服务用户,需要推市场主流电动汽车的智能驾驶功能进行实际测试,并统计数据,现需要开发一个汽车智能测试记录系统,关系模式测试记录(车辆ID,测试时间,待测功能,测试结果,测试员ID,测试员姓名)
(1)车辆ID记录参与测试的车辆的唯一标识。
(2)每辆汽车有多项测试功能(自动泊车、自动导航等)
(3)每次测试仅测试一辆汽车的一项功能,且每次测试有唯一的测试结果(成功、失败)
(4)每项测试只由一名固定的测试成员负责测试,每辆车的每个待测功能只能做一次测试
问题1:确认函数依赖{车辆ID→待测功能)是否成立,说明原因?
一辆车有多项待测功能(如自动泊车、自动导航)。
给定车辆 ID,无法唯一确定待测功能。
问题2:(1)关系模式的候选码?(2)是否存在删除异常,说明原因?
每项测试只由一名固定的测试成员负责测试?每项测试指的是什么属性?要一直读表读到看懂为止,意思是每次测试我们测的功能,一名员工负责。
待测功能 → 测试员ID → 测试员姓名
每辆车的每个待测功能只能做一次测试?
(车辆ID, 待测功能) → 测试时间
且每次测试有唯一的测试结果
(车辆ID, 待测功能) → 测试结果
每辆车的每个待测功能只能做一次测试,那知道车辆和测试什么功能就不用强调是哪天测的了,只会发生一次。
假想,只出现在依赖左边的(车辆ID,待测功能)是候选键
第一先看他能推导出剩余属性吗?第二看他还可以删去主属性吗?
→ 初始:{车辆ID, 待测功能}
→ 依赖 (车辆ID, 待测功能) → 测试时间:加入测试时间
→ 依赖 (车辆ID, 待测功能) → 测试结果:加入测试结果
→ 依赖 待测功能 → 测试员ID:加入测试员ID
→ 依赖 测试员ID → 测试员姓名:加入测试员姓名
→ 闭包 = 全部 6 个属性 ✅发现也删除不了属性了,它就是候选码了。存在非主属性对主属性的传递依赖和部分依赖。
因此是有删除异常的(删某一条记录结果把某个字段在表里的唯一的存在的值搞没了)。
问题3:(1)该关系模式的范式?(2)分解关系模式满足BCNF
由上面一问已知只符合第一范式。
部分依赖和传递依赖都是测试员这个实体的属性造成的,我们把它先丢出去试试看。
原来是:
测试记录(车辆ID,测试时间,待测功能,测试结果,测试员ID,测试员姓名)
改成
测试记录(车辆ID,测试时间,待测功能,测试结果,测试员ID)
测试员:(测试员ID,测试员姓)
可以了吗?不可以,传递依赖丢出去了,部分依赖待测功能 → 测试员ID还在呢
再尝试拆分,把这个小的依赖关系待测功能当成主键
测试记录(车辆ID,测试时间,待测功能,测试结果)
(待测功能,测试员ID)
测试员:(测试员ID,测试员姓)
这下就可以了,这个时候我们再给这个表命名就是了
1.关系模式/范式分析
【说明】
一汽车厂商对配件进行统一管理,设计了相应的数据库,其中一个表记录了维修配件的使用信息。其表结构如下:
维修配件使用表(车牌号,维修时间,配件编码,配件名称,配件供应商,配件仓库编码,仓库地址,维修配件数量)
其中,车牌号和配件编码满足唯一性。假设同一辆车在同一次维修情况下可能需要多种维修配件;一种配件只能存放于一个配件仓库,一种配件只能由一个配件供应商提供。维修时间精确到秒。
【问题1】(7分)
题中给出的维修配件使用表存在数据冗余,请给出具体的冗余属性并说明因此会出现哪些异常?
找冗余属性
"冗余属性"这个概念正是以范式理论为标尺来定义的。
只要是不符合范式设计要求的,都应该列为数据冗余。
所有范式分析题,先搞清楚表是描述什么的,然后确定依赖。
这题要先读完搞明白这个表是做什么用的,它是记录了某一次维修的信息:某车在某时间维修的时候用了什么配件,用了多少...
京A12345, 2025-05-10, P001, 刹车片, ...
京A12345, 2025-05-10, P002, 机油滤芯, ...首先一眼能看出来的依赖有:
配件编码→(配件名称,配件供应商,配件仓库编码)
“一种配件只能存放于一个配件仓库,一种配件只能由一个配件供应商提供”
配件仓库编码→仓库地址
题目有个不严谨的地方,题目说:车牌号和配件编码满足唯一性,很显然同一辆车用同一个配件,存在不同时间多次维修的情况。题目的意思应该是这两个编码不会重复。
应该认为(车牌号, 维修时间, 配件编码)具有唯一性,是主键
Left(只出现在左边) 只决定别人,不被别人决定,必是候选键成员
Right(只出现在右边) 只被别人决定,不决定别人,必不是候选键成员
Left-Right(左右都出现)既决定别人,也被别人决定,可能是候选键成员
None(左右都不出现) 不在任何依赖中出现,必是候选键成员
还剩维修配件数量,这应该是一个数值,我们精确到某一次维修,用了多少配件数量才是不重复的,(车牌号, 维修时间, 配件编码)
(车牌号,维修时间,配件编码)→维修配件数量
接下来就可以分析依赖问题和冗余属性了,非主属性有:
配件名称,配件供应商,配件仓库编码,仓库地址,维修配件数量
补充:主属性指的是候选键里的属性,不是仅指主键里的属性。
配件编码 → 配件名称,是非主属性对候选键(主键)的部分依赖
配件编码 → 配件供应商,部分依赖
配件编码 → 配件仓库编码 部分依赖
配件编码 → 配件仓库编码→ 仓库地址
(车牌号, 维修时间, 配件编码) → 维修配件数量 完全依赖✅
因此冗余属性:配件名称,配件供应商,配件仓库编码,仓库地址
插入异常:有新人(新数据)没“主键”领不进来(主键缺失)。
删除异常:删掉特定数据,顺带把其他信息也删没了(信息丢失)。
更新异常:改一个事实,要改 N 个地方,漏了就乱(修改复杂、数据不一致)。
只要在分析中发现了部分依赖或传递依赖,就可以立刻“锤定”该表存在插入、删除和更新三种异常,无一例外。
出现的异常有:存在插入异常,修改异常和删除异常。
模式分解
【问题2】(8分)
维修配件使用表是否满足BCNF?如果不满足,请对其进行模式分解,使分解后的关系模式满足BCNF,并标记出主键和外键。
由于存在传递依赖和部分依赖,不满足
对于模式拆分的题目,我们统一需要搞清楚:1️⃣主键是什么?2️⃣依赖是什么?丢掉造成冗余的依赖,按独立的实体划分一个实体一张表
这些我们在第一问中已经分析。
配件编码 → (配件名称, 配件供应商, 配件仓库编码)
括号里的三个属性,都只由 配件编码 决定,“一种配件只能由一个配件供应商提供”、“只能存放于一个配件仓库”,这也叫1对1关系。
如果还出现了其他的东西,那就说明出现了部分依赖,那就说明出现了冗余,我们拆分模式就是要把冗余丢出去
维修配件使用表(车牌号,维修时间,配件编码,配件名称,配件供应商,配件仓库编码,仓库地址,维修配件数量)
模式1️⃣:把决定因素 配件编码 作为新表的主键,其余属性都由这个主键决定
配件(配件编码, 配件名称, 配件供应商, 配件仓库编码)
主键:配件编码
外键:配件仓库编码,它是引用下面仓库表
模式2️⃣:依据:配件仓库编码 → 仓库地址 这个依赖。
把决定因素 配件仓库编码 作为新表的主键,
仓库(配件仓库编码, 仓库地址)
主键:配件仓库编码,没有外键
模式3:原来的大表只剩下了主键和被主键完全决定的属性。
(车牌号,维修时间,配件编码)→维修配件数量
维修记录表(车牌号, 维修时间, 配件编码, 维修配件数量)
主键是(车牌号,维修时间,配件编码),外键是配件编码,引用自配件表
2.关系模式/范式分析
【说明】
某卡丁车场地为了方便车手在线上查询自己的圈速成绩,设计了相应的关系模型。模型中有三个表:
冲线记录表(序列号,日期,冲线时刻,圈速,车号,组别,手机号,车手姓名 );
赛车表(车号,组别,车型 );
车手表(车手姓名,手机号,年龄,性别 )。
其中序列号唯一确定一条冲线记录,车型和组别可由车号确定,车手手机号唯一,车手姓名可重复。
【问题1】(3分)
冲线记录表中是否含有数据冗余?如果存在冗余,请列出冗余属性。
候选键 能唯一标识一行的属性(组)
主键 从候选键中选出来的那一个
主属性 出现在任意候选键中的属性
题目:序列号唯一确定一条冲线记录。说明序列号本身就是一个候选键。在这题中即是候选键,也是主键,是唯一的主属性。
此题不存在任何非主属性的部分依赖,但是存在很多间接依赖。
车型和组别可由车号确定,车手手机号唯一
车号 → 组别 ❌ 传递依赖(序列号→车号→组别)
手机号 → 车手姓名 ❌ 传递依赖(序列号→手机号→车手姓名)
因此,存在数据冗余,冗余属性为:组别、车手姓名
外键分析
【问题2】(6分)
请分别给出冲线记录表、赛车表和车手表的主码和外码。
外键是用于建立两张表之间逻辑关联的“桥梁”,而这座“桥”的起点,一定是另一头的主键。
属性X是表A的外键,当且仅当X是表B的主键!!
车手手机号唯一,车手姓名可重复。
车手表的主键不是姓名,是手机号
塞车表的主键是车号
冲线记录表的主键是序列号
冲线记录表(车号) ────→ 赛车表(车号)
冲线记录表(手机号) ────→ 车手表(手机号)因此冲线记录表中的车号和手机号是外键
其余的两个表没有外键,因为它们剩余的属性,并非其他表的主键
【问题3】(6分)
题干描述的冲线记录表是否满足3NF?如果不满足,请给出导致不满足3NF的函数依赖关系,并用50字以内的文字简要说明解决方案。
由于表中存在非主属性对主属性的传递依赖,所以不满足3NF。
解决方案:
消除冲线记录表中的传递依赖,也就是删除冲线记录表中的组别、车手姓名这两个字段。
3.关系模式/范式分析
【说明】
某市居委会在新冠病毒疫情期间需分配社区人员到辖区内各个小区,协助小区物业人员进行业主出入登记及体温检测工作。居委会为高效完成工作并记录必要的工作信息,设计了相应的数据库。其中有一个表用来记录工作人员在各个小区的分布情况及每天工作时长。表的结构如下:
人员分配(人员编号,人员姓名,小区编号,物业经理姓名,人员职责)。
其中人员编号和小区编号唯一,人员职责用于记录该人员需配合小区完成的工作,假设每个人员在同一个小区只负责一项工作,但在不同小区可以负责不同的工作。请回答以下问题。
【问题1】(6分)
给出人员分配表中成立且左侧只有一个属性的所有函数依赖关系。题中设计的人员分配表是否满足2NF,请用100字以内的文字说明原因。
人员编号和小区编号唯一
每个人员在同一个小区只负责一项工作,但在不同小区可以负责不同的工作。
人员编号 → 人员姓名
小区编号 → 物业经理姓名
人员可能在多个不同小区工作,人员编号无法得出人员职责
不过每个人员在同一个小区只负责一项工作,
(人员编号,小区编号)→人员职责,这两个主属性加起来才能标识唯一的一行。
不是2NF,因为人员分配表的主键是(人员编号,小区编号),存在非主属性对主键的部分依赖。
【问题2】(3分)
如果要将人员分配表规范化为满足3NF,请用100字以内的文字简要说明解决方案。
第一问已知主键,已知依赖关系
部分依赖造成了冗余,我们将冗余属性:人员姓名、物业经理姓名拆离,一个实体一张表
拆分为三个表:
人员表(人员编号,人员姓名)
小区表(小区编号,物业经理姓名)
分配表(人员编号,小区编号,人员职责)
【问题3】(6 分)
请给出问题2设计结果中各个表的主键和外键。
人员表的主键为人员编号,无外键。
小区表的主键为小区编号,无外键。
责任表的主键为人员编号和小区编号,外键是人员编号和小区编号。
一个属性同时是主键又是外键
一个属性完全可以同时是主键和外键。这种情况非常常见,尤其是在多对多关系的关联表中。
4.关系模式/范式分析
【说明】
为防控新冠疫情,一些公共设施需要定期消毒,管理部门为高效完成工作并记录必要的工作信息,设计了相应的数据库,其中有一个表用来记录公共汽车的消毒情况,表的结构如下:
消毒记录(日期,车牌号,行驶路线,消毒人员工号,消毒人员姓名)
其中车牌号和消毒人员工号唯一,同一辆车保持固定的行驶路线。假设同一人员每天可以负责多辆车的消毒工作。
【问题1】(6分)
给出消毒记录表中成立且左侧只有一个属性的所有函数依赖关系。题中设计的消毒记录表是否满足2NF?请用100字以内的文字说明原因。
"同一辆车保持固定的行驶路线",“车牌号和消毒人员工号唯一”
车牌号 → 行驶路线
消毒人员工号 → 消毒人员姓名
由于存在非主属性对主键的部分依赖,不满足2NF
唯一和候选键的关系/缩减候选键
(车牌号,消毒人员工号)并非候选键,显然存在不同日期相同的车和人的因素。
题目说车牌号和消毒人员工号唯一,仅能说明它们在自己的属性中不会像人名、年龄一样重复,而它们在表中可能会冗余重复几行,这和身份证、序列号那种整个表里面全局唯一 一行是不一样的。
题目说唯一,单单只是不重复的唯一,并不能说明它就是候选键之一,它也可能是非主属性!!!
主键是(车牌号,消毒人员工号,日期),如果题目强调一辆车一天只消毒一次,那主键就变成(车牌号,日期),连唯一的消毒人员工号都变成了非主属性。
【问题2】 (6分)
如果要将消毒记录表规范化为满足3NF,请用100字以内的文字简要说明解决方案,并给出各个新表的主码和外码。
1️⃣找到主键2️⃣确认依赖3️⃣拆走冗余,一个实体一张表
由于消毒记录表不满足2NF,需要将消毒记录表进行拆分成多个表,拆分的表如下:
消毒记录1(车牌号,行驶路线)主码:车牌号
消毒记录2(消毒人员工号,消毒人员姓名)主码:消毒人员工号
消毒记录3(车牌号,日期,消毒人员工号)主码:车牌号,日期,外码:车牌号,消毒人员工号
由于拆分后的三个表都不存在非主属性对主属性的部分和传递函数依赖,所以都满足3NF。
关系模式额外添加属性
【问题3】 (3分)
如果每辆车每日有多次消毒,需要记录每次消毒的消毒时间,在问题2设计结果的基础上,如何在不破坏3NF且不增加冗余的前提下做到?请简单说明方案。
先看清楚它要记录什么?消毒时间
分析怎么样不添加冗余就是分析依赖关系
如果新增表,新增的表里面哪些属性就可以保证不重复?
车牌号,日期
单独车牌号,存在不同天数都是下午X点清洁的可能
单独日期,存在同一天不同车辆同时清洁的可能
方法1️⃣添加消毒记录4(车牌号,日期,消毒时间),可以唯一标识一行
如果插入到一个表中,看看是否存在部分依赖和传递依赖
方法2️⃣插入,变成消毒记录表(日期,车牌号,消毒时间,消毒人员工号)
(日期, 车牌号, 消毒时间) → 消毒人员工号 完全依赖
5.关系模式/范式分析
【说明】
某快递公司对每个发出的快递进行跟踪管理,需要建立一个快递跟踪管理系统,对该公司承接的快递业务进行有效管理。
【需求描述】
1.公司在每个城市的每个街道都设有快递站点。这些站点负责快递的接收和投递。站点信息包括站点地址、站点名称、责任人、一个联系电话、开始营业时间、结束营业时间。 每个站点每天的营业时间相同。每个站点只能有一个责任人。
2.系统内需记录快递员、发件人的基本信息。这些信息包括姓名、身份证号、一个联系地址、一个联系电话。快递站点的责任人由快递员兼任,且每个快递站点只有一个责任人。每个快递员只负责一个快递站点的揽件和快递派送业务。发件人和快递员需实名认证。
3.快递需要提供详实的信息,包括发件人姓名、身份证号、一个发件人电话号码、发件人地址、收件站点、收件人姓名、收件地址、一个收件人电话、投递时间、物品类别、 物品名称及物品价值。每个发件人和收件人在系统里只能登记一个电话和地址。
4.每个快递员接手一份快递后,需在系统中录入每个快递的当前状态信息,包括当前位置、收到时间、当前快递员和上一快递员。状态信息包括待揽件、投递中、已签收。 如果快递已签收,应记录签收人姓名及一个联系电话。每个快递在一个站点只能对应一个负责的快递员。
注:试题不需要考虑快递退回的相关问题。
【逻辑结构设计】
根据上述需求,设计出如下关系模式:
快递(快递编号,收件人姓名,收件地址编号,收件人电话,投递时间,物品类别,物品名称,物品价值),其中收件地址编号是地址实体的地址编号。
快递员(姓名,身份证号,电话号码,联系地址编号,工作站点编号)
快递站点(站点编号,站点名称,责任人编号,站点地址编号,开始营业时间,联系电话,结束营业时间)。责任人编号是负责该站点的快递员的身份证号。
地址(地址编号,所在省,所在市,所在街道,其他),其他信息是需补充的地址信息。
快递投递(快递编号,快递员编号,发件人姓名,发件人身份证号,发件人电话号码, 发件人地址编号),其中发件人地址编号为发件人地址的地址编号,揽件站点编号为接收该快递的站点编号。
快递跟踪(快递编号,当前负责人编号,前一负责人编号,当前状态,收到时间, 当前站点编号)。
快递签收(快递编号,签收人姓名,签收人联系电话)。
根据以上描述,回答下列问题:
【问题1】(6分)
对关系“快递投递”,请回答以下问题:
(1) 列举出所有候选键。
(2) 它是否为3NF,用100字以内文字简要叙述理由。
(3) 将其分解为BCNF,分解后的关系名依次为:快递投递1,快递投递2,…,并用下划线标示分解后各关系模式的主键。
快递投递(快递编号,快递员编号,发件人姓名,发件人身份证号,发件人电话号码, 发件人地址编号)
快递编号可以唯一标识该行所有剩余信息,候选键是快递编号
依赖分析:
快递编号 → 快递员编号
快递编号 → 发件人身份证号→ 发件人姓名,发件人电话号码,发件人地址编号
存在非主属性对主属性的传递依赖,不属于3NF
模式分解:1️⃣确认主键2️⃣确认依赖3️⃣拆分冗余属性,一个实体一张表
快递投递1(快递编号,快递员编号,发件人身份证号)
快递投递2(发件人身份证号,发件人姓名,发件人电话号码,发件人地址编号)
双向依赖同时成立
【问题2】(6分)
对关系“快递跟踪”,请回答以下问题:
(1) 列举出所有候选键。
(2) 它是否为2NF,用100字以内文字简要叙述理由。
(3) 将其分解为BCNF,分解后的关系名依次为:快递跟踪1,快递跟踪2,…,并用下划线标示分解后各关系模式的主键。
快递跟踪(快递编号,当前负责人编号,前一负责人编号,当前状态,收到时间, 当前站点编号)。
仔细阅读题目,每个站点只能有一个责任人,每个快递员只负责一个快递站点的揽件和快递派送业务。
当前站点编号 → 当前负责人编号也对
当前负责人编号 → 当前站点编号也对
不管我们这个题认为候选键是(快递编号,当前站点编号),还是(快递编号,当前负责人编号),它都不影响这道题就是出现了部分依赖,无法达到2NF。
模式分解:
(快递编号,当前负责人编号/当前站点编号) → 当前状态
(快递编号,当前负责人编号/当前站点编号) → 收到时间
(快递编号,当前负责人编号/当前站点编号) → 前一负责人编号
如果是(快递编号,当前站点编号)
把当前站点编号 → 当前负责人编号这个部分依赖造成的冗余丢出去,一个实体一张表。
快递跟踪A2(当前站点编号,当前负责人编号)
快递跟踪A1(快递编号,当前站点编号,前一负责人编号,当前状态,收到时间)
如果是(快递编号,当前负责人编号)
快递跟踪B1(快递编号,当前站点编号,前一负责人编号,当前状态,收到时间)
快递跟踪B2(当前负责人编号,当前站点编号)
新增关系模式
【问题3】(3分)
快递公司会根据快递物品和距离收取快递费,每件快递需由发件人或收件人支付快递费给公司。同一个发件人同时发起多个快递,必须分别支付。快递公司提供预支付和到付两种支付方式。为了统计快递费的支付情况(详细金额和时间),试增加“快递费支付”关系模式,用100字以内文字简要叙述解决方案。
注意题目要求,金额和时间是必须要有的,还要留意到支付方式有两种,支付人既可以是到付也可以是寄付。支付人的其他信息在其他表里已有。
然后分析上题中的哪些属性需要继续用。
新增关系模式:快递费支付(快递编号,支付方式,支付金额,支付时间,支付人类型)。
主键为快递编号,外键为快递编号(引用快递表)。支付与快递一对一关联,完全依赖于主键,满足 3NF 且无冗余。
6.关系模式/范式分析
【说明】
某社会救助基金会每年都会举办多项社会公益救助活动,需要建立一个信息系统,对之进行有效管理。
【需求描述】
1.任何一个实名认证的个人或者公益机构都可以发起一项公益救助活动,基金会需要记录发起者的信息。如果发起者是个人,需要记录姓名、身份证号和一个电话号码;如果发起者是公益机构,需要记录机构名称、统一社会信用代码、一个电话号码、唯一的法人代表身份证号和法人代表姓名。一个自然人可以是多个机构的法人代表。
2.公益救助活动需要提供详实的资料供基金会审核,包括被捐助人姓名、身份证号、 一个电话号码、家庭住址。
3.基金会审核并确认项目后,发起公益救助的个人或机构可以公开宣传并募捐,募捐得到的款项进入基金会账户。
4.发起公益救助的个人或机构开展救助行动,基金会根据被捐助人所提供的医疗发票或其他信息,直接将所筹款项支付给被捐助者。
5.救助发起者针对任一被捐助者的公益活动只能开展一次。
【逻辑结构设计】
根据上述需求,设计出如下关系模式:
公益活动(发起者编号,被捐助者身份证号,发起者电话号码,发起时间,结束时间, 募捐金额),其中对于个人发起者,发起者编号为身份证号;对于机构发起者,发起者编号为统一社会信用代码。
个人发起者(姓名,身份证号,电话号码)
机构发起者(机构名称,统一社会信用代码,电话号码,法人代表身份证号,法人代表姓名)
被捐助者(姓名,身份证号,电话号码,家庭住址)
【问题1】(6 分)
对关系“机构发起者”,请回答以下问题:
(1) 列举出所有候选键。
(2) 它是否为3NF ,用100字以内文字简要叙述理由。
(3) 将其分解为 BCNF 范式,分解后的关系名依次为:机构发起者1,机构发起者 2 ,……, 并用下划线标示分解后的各关系模式的主键。机构发起者(机构名称,统一社会信用代码,电话号码,法人代表身份证号,法人代表姓名)
候选键是:统一社会信用代码
统一社会信用代码 → 机构名称,电话号码,法人代表身份证号,法人代表姓名
法人代表身份证号 → 法人代表姓名
存在非主属性对候选键的传递依赖,不满足3NF
模式分解:因为传递依赖:法人代表身份证号 → 法人代表姓名造成了冗余,我们就把它拆分,法人这个实体独立一张表
机构发起者1(统一社会信用代码,机构名称,电话号码,法人代表身份证号)
主键:统一社会信用代码
外键:法人代表身份证号(引用机构发起者2)
机构发起者2(法人代表身份证号,法人代表姓名)
主键:法人代表身份证号
【问题2】(6 分)
对关系“公益摇动 ”,请回答以下问题:
(1)列举出所有候选键。
(2)它是否为2NF ,用100字以内文字简要叙述理由。
(3)将其分解为 BC 范式,分解后的关系名依次为:公益活动1,公益活动 2 ,……, 并用下划线标示分解后的各关系模式的主键。公益活动(发起者编号,被捐助者身份证号,发起者电话号码,发起时间,结束时间, 募捐金额)
题目问是否为3NF,隐含的意思就是有部分依赖/有传递依赖,题目问是否为2NF,隐含的意思就是有部分依赖。
题目:“救助发起者针对任一被捐助者的公益活动只能开展一次”
候选键是(发起者编号,被捐助者身份证号)
有可能是(发起者编号,发起时间)吗?
由于多个项目的起始时间可能相同,而结束时间可能不同,所以发起时间不能用函数决定结束时间。同时也有可能多个项目的起始和结束时间是相同的。所以发起时间和结束时间不能用函数决定一次活动。
发起者编号 → 发起者电话号码
(发起者编号,被捐助者身份证号) → 发起时间,结束时间,募捐金额
候选键为(发起者编号,被捐助者身份证号)。非主属性"发起者电话号码"只依赖于发起者编号,存在非主属性对候选键的部分函数依赖,违反 2NF。
模式分解:
部分依赖:发起者编号 → 发起者电话号码造成冗余,将其拆分,发起者这个实体单独一张表
公益活动1(发起者编号,被捐助者身份证号,发起时间,结束时间,募捐金额)主键:(发起者编号,被捐助者身份证号)
公益活动2(发起者编号,发起者电话号码)主键:发起者编号
新增关系模式
【问题3】(3分)
基金会根据被捐助人提供的医疗发票或其他信息,将所筹款项支付给被捐助者。可以存在分期多次支付的情况,为了统计所筹款项支付情况(详细金额和时间) ,试增加“支付记录”关系模式,用100字以内文字简要叙述解决方案。
分析上题中的哪些属性需要继续用,肯定需要被捐助者身份证号,还需要发起者编号吗?同一个被捐助者,可以被不同的发起者分别救助。
支付记录(支付编号,发起者编号,被捐助者身份证号,支付金额,支付时间,被捐助人的相关信息)
被捐助人提供的医疗发票或其他信息,这种描述不清的,我们可以自己取字段名,自己补充说明,能满足题目要求,言之有理即可
(被捐助人的相关信息为医疗发票或其他信息),支付编号唯一标识每一次支付。
7.关系模式/范式分析
【说明】
某小区由于建设时间久远,停车位数量无法满足所有业主的需要,为公平起见,每年进行一次抽签来决定车位分配。小区物业拟建立一个信息系统,对停车位的使用和收费进行管理。
【需求描述】
(1)小区内每套房屋可能有多名业主,一名业主也可能在小区内有多套房屋。业主信息包括业主姓名、身份证号、房号、房屋面积,其中房号不重复。
(2)所有车位都有固定的编号,且同一年度所有车位的出租费用相同,但不同年份的出租费用可能不同。
(3)所有车位都参与每年的抽签分配。每套房屋每年只能有一次抽签机会。抽中车位的业主需一次性缴纳全年的车位使用费用,且必须指定唯一的汽车使用该车位。
(4)小区车辆出入口设有车牌识别系统,可以实时识别进出的汽车车牌号。为方便门卫确认,系统还需登记汽车的品牌和颜色。
【逻辑结构设计】
根据上述需求,设计出如下关系模式:
业主(业主姓名,业主身份证号,房号,房屋面积)
车位(车位编号,房号,车牌号,汽车品牌,汽车颜色,使用年份,费用)
【问题1】(6分)
对关系“业主”,请回答以下问题:
(1)给出“业主”关系的候选键。
(2)它是否为2NF,用60字以内文字简要叙述理由。
(3)将其分解为BCNF,分解后的关系名依次为:A1,A2,...,并用下划线标示分解后的各关系模式的主键。
业主(业主姓名,业主身份证号,房号,房屋面积)
每套房屋可能有多名业主,一名业主也可能在小区内有多套房屋。其中房号不重复。
“业主”关系的候选键为:房号,业主身份证号。
业主身份证号 → 姓名
业主身份证号 → 联系电话
房号→房屋面积
存在非主属性(姓名、联系电话、房屋面积)对候选键 (房号, 业主身份证号) 的部分函数依赖。不满足2NF
模式分解:把业主信息、房屋面积这个造成了部分依赖的实体拆分
A1(业主姓名, 业主身份证号)
A2( 房号,房屋面积)
A3( 业主身份证号,房号)
候选键不唯一
【问题2】(6分)
对关系“车位”,请回答以下问题:
(1)给出“车位’’关系的候选键。
(2)它是否为3NF,用60字以内文字简要叙述理由。
(3)将其分解为BCNF,分解后的关系名依次为:B1,B2,...,并用下划线标示分解后的各关系模式的主键。
车位(车位编号,房号,车牌号,汽车品牌,汽车颜色,使用年份,费用)所有车位都参与每年的抽签分配。因此不可能是单独车位编号。
(车位编号, 使用年份) → 车牌号
抽中车位的业主需指定唯一的汽车
(房号, 使用年份) → 车位编号
每套房屋每年只能有一次抽签机会
使用年份 → 费用
同一年度所有车位的出租费用相同
车牌号 → 汽车品牌, 汽车颜色
(车位编号, 使用年份)和(房号, 使用年份)是候选键
这一行决定了此题不论怎么分析必然存在非主属性对候选键的部分依赖,2NF
(车牌号,使用年份) 有可能也是候选键,如果业主有两套房,却只有一辆车就会出现此种情况决定不了唯一一行。如果一辆车在同一年只能被指定一次,那就是候选键。
这题和之前的一题一样都是候选键不唯一,但是我们要拆分的是不符合要求的非主属性,所以不论怎么模式拆分,结果一定有费用和汽车属性这两个实体变成单独的一张表。
B1(使用年份,费用)
B2(车牌号,汽车品牌,汽车颜色)
B3(车位编号,使用年份,房号,车牌号)
候选键不唯一造成的问题只是,主键是候选键中的其一,可能有多种主键
【问题3】(3分)
若临时车辆进入小区,按照进入和离开小区的时间进行收费(每小时2元)。试增加“临时停车”关系模式,用100字以内文字简要叙述解决方案。
临时停车(车牌号,进入时间,离开时间)。
需要注意的是:这三个属性是必须有的,也可出现其他属性。
对于收费方来说,他只关心你停了多久来收费,他不关心你停哪里,而且外部车辆可能停的地方是没有车位号的
8.表格形式分析关系模式
【说明】
某地人才交流中心为加强当地企业与求职人员的沟通,促进当地人力资源的合理配置,拟建立人才交流信息网。
【需求描述】
1.每位求职人员需填写《求职信息登记表》(如表4-1所示),并出示相关证件,经工作人员审核后录入求职人员信息。表中毕业证书编号为国家机关统一编码,编号具有唯一性。每个求职人员只能填写一部联系电话。
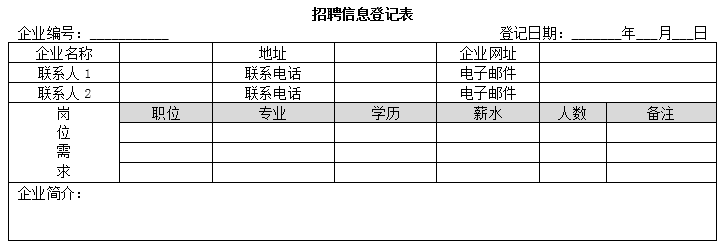
2.每家招聘企业需填写《招聘信息登记表》(如表4-2所示),并出示相关证明及复印件,经工作人员核实后录入招聘企业信息。表中企业编号由系统自动生成,每个联系人只能填写一部联系电话。
3.求职人员和招聘企业的基本信息会在系统长期保存,并分配给求职人员和招聘企业用于登录的用户名和密码。求职人员登录系统后可登记自己的从业经历、个人简历及特长,发布自己的求职意向信息;招聘企业的工作人员登录系统后可维护本企业的基本信息,发布本企业的岗位需求信息。
4.求职人员可通过人才交流信息网查询企业的招聘信息并进行线下联系;招聘企业的工作人员也可通过人才交流信息网查询相关的求职人员信息并进行线下联系。
5.求职人员入职后应修改自己的就业状态(在岗/求职);招聘企业在发布需求岗位有人员到岗后也应该及时修改需求人数。
表4-1
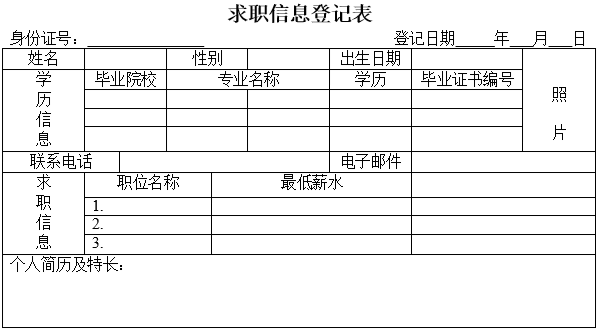
表4-2
【逻辑结构设计】
根据上述需求,设计出如下关系模式:
个人信息(身份证号,姓名,性别,出生日期,毕业院校,专业名称,学历,毕业证书编号,联系电话,电子邮件,个人简历及特长)
从业经历(身份证号,起止时间,企业名称,职位)
求职意向(身份证号,职位名称,最低薪水)
企业信息(企业编号,企业名称,地址,企业网址,联系人,联系电话,电子邮件,企业简介)
岗位需求(企业编号,职位,专业,学历,薪水,人数,备注)
【问题1】(6分)
对关系“个人信息”,请回答以下问题:
(1)列举出所有候选键。
(2)它是否为3NF,用60字以内文字简要叙述理由。
(3)将其分解为BC范式,分解后的关系名依次为:个人信息1,个人信息2,…,并用下划线标示分解后的各关系模式的主键。个人信息(身份证号,姓名,性别,出生日期,毕业院校,专业名称,学历,毕业证书编号,联系电话,电子邮件,个人简历及特长)
候选键:毕业证书编号
注意看表格!!!每个人有多条毕业证书编号(教育经历多段),身份证号完全不可以标识唯一的一行
“个人信息”关系的函数依赖集为
毕业证书编号→(毕业院校,专业名称,学历,身份证号),
身份证号→(姓名,性别,出生日期,联系电话,电子邮件,个人简历及特长)
存在非主属性对候选键的传递依赖,属于 3NF
模式分解,把个人身份这个造成传递依赖的实体拆分成独立的一张表
个人信息1(身份证号,姓名,性别,出生日期,联系电话,电子邮件,个人简历及特长)
个人信息2(身份证号,毕业证书编号,毕业院校,专业名称,学历)
【问题2】(6分)
对关系“企业信息”,请回答以下问题:
(1)列举出所有候选键。
(2)它是否为2NF,用60字以内文字简要叙述理由。
(3)将其分解为BC范式,分解后的关系名依次为:企业信息1,企业信息2,…,并用下划线标示分解后的各关系模式的主键。企业信息(企业编号,企业名称,地址,企业网址,联系人,联系电话,电子邮件,企业简介)
注意看表格!!!每个企业有多个联系人
(1)企业编号和联系人
(2)不是,非主属性对主键存在部分依赖
(3)企业和联系人两个实体单独划分为表
企业信息1(企业编号,企业名称,地址,企业网址,企业简介)
企业信息2(企业编号,联系人,联系电话,电子邮件)
触发器知识
【问题3】(3分)
若要求个人的求职信息一经发布,即由系统自动查找符合求职要求的企业信息,填入表R(身份证号,企业编号),在不修改系统应用程序的前提下,应采取什么方法来实现,用100字以内文字简要叙述解决方案。
在数据库端创建触发器,当向求职意向表插入记录时,自动查询岗位需求表中匹配该求职者职位、学历等条件的企业,将(身份证号,企业编号)插入表R。无需修改应用程序,通过数据库内部机制实现实时匹配。