
一、2025年真题
1.设有关系:学生(学号,姓名,性别,年龄,系号),能正确统计出不同系的个数的SQL语句为SELECT()FROM学生;
可以查询姓名中第一个字为“王”字的学生信息的SQL语句为SELECT *FROM学生WHERE 姓名 LIKE()。
A.COUNT(DISTINCT 系号)
B.COUNT(系号)
C.COUNT(*)
D.COUNT(DISTINCT 姓名)
注意看题目要求的是找出系有多少个,在学生表中会出现很多重复的系因此需要去重选A
A'王%’
B.'%王%′
C.'王_′
D'王'
考察下划线与百分号的区别
2.某高校教务系统中,存在学生、课程、选课记录表。为了保证学生和课程记录唯一且不能为空,应使用();为了保证学生在选课的时候,所选的课程均为学校正常开设可选的课程,在选课记录和课程之间,应建立()。
A.check约束
B.外键约束
C.default约束
D.主键约束
看到题目说唯一非空即可想到主键
A.default约束
B.check约束
C.主键约束
D.外键约束
3.在DBMS中,当用户创建主键约束时,DBMS一般会自动创建()以提高查询效率。
A、视图
B、索引
C、触发器
D、存储过程
4.以下关于GROUP BY和HAVING子句的说法,正确的是?
A、HAVING只能用于过滤聚合函数的结果
HAVING 也可过滤分组列(GROUP BY 中的列)
B、GROUP BY用于分组后筛选聚合结果,HAVING用于分组前筛选原始数据
C、GROUP BY必须与HAVING一起使用
GROUP BY 可以单独使用
D、HAVING 可以对未分组的列进行过滤
一个列既不在 GROUP BY 中,也没有被聚合函数包裹,才不能在 HAVING 中使用。
5.建表时,定义字段用的是什么?
A、数据控制语言
B、数据定义语言
C、数据控制语言
D、数据查询语言
数据查询(DQL):SELECT是SQL中用得最多的动词。
数据定义(DDL):CREATE、ALTER、DROP用于创建表、修改表和删除表
数据操纵(DML):INSERT、UPDATE、DELETE用于数据插入、修改和删除
数据控制(DCL):GRANT、REVORK用于数据库对象访问权限授予和收回
6.表B引用了表A的主键,删除表A的记录时
A、禁止删除
三、按知识点分类的往年题:
章节考取的阅读、使用SQL语句能力大类不分类
1.某超市的商品(商品号,商品名称,生产商,单价)和仓库(仓库号,地址,电话,商品号,库存量)两个基本关系如表1和表2所示。
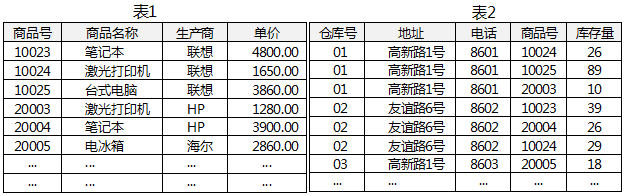
a.仓库关系的主键是( 仓库号,商品号 ),该关系没有达到第三范式的原因是( 2 );
b.查询联想生产的激光打印机的总库存量的SQL语句如下:
SELECT 商品名称,( 3 )
FROM 商品,仓库
WHERE( 4 )AND( 5 ) ;
c.若仓库关系的地址不能为空,请将下述仓库关系SQL语句的空缺部分补充完整。CREATE TABLE 仓库(仓库号CHAR(2),
地址 CHAR(20)( 6 ) ,
电话 CHAR(20),
商品号 CHAR(5),
库存量NUMERIC(5),
( 7 ) ,
( 8 ) );
请作答:第 2 题
A没有消除非主属性对码的部分函数依赖,如:仓库号→电话
B没有消除非主属性对码的部分函数依赖,如:地址→电话
不存在地址→电话这个依赖
C只消除了非主属性对码的部分函数依赖,而未消除传递函数依赖
部分依赖没消除,根本就不满足2NF,更别说3NF了,不要因为题目问的是3NF就去选3NF的条件
D只消除了非主属性对码的传递函数依赖,而未消除部分函数依赖
分析范式,先看关系中的属性,还有哪些是候选键/主属性/非主属性,试着列出每一条依赖
仓库关系:仓库(仓库号,地址,电话,商品号,库存量)
主键:(仓库号,商品号)
仓库号 → 地址:地址只由仓库号决定,与商品号无关
仓库号 → 电话:电话只由仓库号决定,与商品号无关
(仓库号,商品号)→ 库存量:库存量由完整的键决定
地址只依赖于仓库号(主键的一部分),这是部分函数依赖
电话也只依赖于仓库号(主键的一部分),也是部分函数依赖
所以仓库关系 不满足 2NF。
请作答:第 3 题
A NUMBER(库存量)NUMBER 是数据类型,不是函数。
B SUM(库存量)
C COUNT(库存量)统计行数!不是求总和
D TOTAL(库存量)SQL数据库中不存在total这个用法
请作答:第 4 题
A生产商=联想
字符串不加引号会被认为是列名
B仓库.生产商=联想
C生产商=‘联想’
只有一张表有生产商,所以前缀是可以省略的
D仓库.生产商=‘联想’
仓库这个表里跟没有生产商这个字段
第5题:
商品名称=‘激光打印机’ AND 商品.商品号=仓库.商品号
请作答:第 6 题
A NOT NULL
仔细阅读题目:仓库地址不能为空
第7题:
PRIMARY KEY(仓库号,商品号)
一开始就分析了仓库号和商品号是主键
外键:FOREIGN KEY/REFERENCES
请作答:第 8 题
A FOREIGN KEY(仓库号)REFERENCES 仓库号
语法错误,在任何情况下都不能简写
B FOREIGN KEY(仓库号)REFERENCES 仓库(仓库号)
自己引用自己,没有意义
C FOREIGN KEY(商品号)REFERENCES 仓库(商品号)
自己引用自己,没有意义
D FOREIGN KEY(商品号)REFERENCES 商品(商品号)
外键约束的标准格式:
FOREIGN KEY (本表列名) REFERENCES 外表名(外表列名)
撤回:REVOKE/RESTRICT/CASCADE
9.撤销 U5 对 Emp 表的查询权限,并收回 U5 授予其它用户的该权限,SQL 语句是 ()。
A REVOKE SELECT ON TABLE Emp FROM U5 CASCADE;
标准SQL中收回权限的基本语法是:
REVOKE<权限>FROM<对象数据><对象名>FROM<用户>[RESTRICT|CASCADE];
CASCADE表示级联收回,即收回用户权限并同时收回该用户授予其他用户的该权限。
B REVOKE SELECT ON TABLE Emp FROM U5 RESTRICT;
RESTRICT 表示如果 U5 已经把权限转授出去,就拒绝执行这条回收语句,相当于没执行命令(默认)
C REVOKE QUERY ON TABLE Emp FROM U5 CASCADE;
QUERY指的是向数据库发出的任何请求,不是命令
D GRANT SELECT ON TABLE Emp TO U5 WITH GRANT OPTION;
GRANT 是授予权限,不是收回权限,而且 WITH GRANT OPTION 表示允许 U5 再转授给别人,和回收权限的要求反了。
24-25
收回用户li对表employee的查询权限,同时级联收回li授予其他用户的该权限,SQL语句为:( REVOKE ) select ON TABLE employee FROM li( 25 ) ;
请作答:第 25 题
A RESTRICT
B CASCADE
C WITH GRANT OPTION
D WITH CHECK OPTION
用于视图,通过视图修改数据时必须符合视图条件
87
授权语句GRANT中,以下关于WITH GRANT OPTION子句的叙述中,正确的是( )。
用于指明获得权限的用户还可以将该权限赋给其他用户
题库2.14
数据库管理员对经理U1、U2赋予表D和M的插入权限。U1赋予实习生U3对表D的插入权限。U2发现当U3说服顾客办理信用卡后,每次都要找他注册,为了减少工作量,他也对U3赋予表M的插入权限。一段时间后,U1离职,数据库管理员收回权限,执行的SQL语句为REVOKE M FROM U1 CASCADE,此时U3仍具有的权限为( )。
A无任何权限
B插入D表的权限
C插入M表的权限
D插入D和M表的权限
仔细读题,命令收回 U1 对 M 表的 INSERT 权限,并级联收回 U1 转授出去的 M 权限。U1 根本没给 U3 授予过 M 权限
创建表主码和外码的要求
10.11.设有职工关系Emp(Eno,Ename,Esex,EDno)和部门关系Dept(Dno,Dname,Daddr),创建这两个关系的SQL语句如下:
CREATE TABLE Emp(
Eno CHAR(4),
Ename CHAR(8),
Esex CHAR(1) CHECK(Esex IN (‘M’, ‘F’)),
EDno CHAR(4) REFERENCES Dept(Dno),
PRIMARY KEY (Eno)
);
CREATE TABLE Dept(
Dno CHAR(4) NOT NULL UNIQUE,
Dname CHAR(20),
Daddr CHAR(30)
);
直接运行该语句,DBMS会报错,原因是:( 10 )。若经过修改,上述两个表创建完毕之后(尚无数据),则下述语句中能被执行的是( 11 )。
请作答:第 10 题
A创建表Dept时没有指定主码
ept 表用了 NOT NULL UNIQUE,虽然不是用 PRIMARY KEY 显式声明,但在大多数 DBMS 中可以当作候选码使用,不是导致报错的直接原因。
B创建表Dept时没有指定外码
C创建表Emp时,被参照表Dept尚未创建
Emp 建表时发现参照了一个不存在的表,会直接报错。
D表Emp的外码EDno与被参照表Dept的主码Dno不同名
没有这个要求,只要类型匹配就行。
请作答:第 11 题
A INSERT INTO Emp VALUES(‘e001’, ‘王’, ‘M’, ‘d1’);
外键 'd1' 在空的 Dept 表中不存在,违反外键约束
B INSERT INTO Emp VALUES(NULL, ‘王’, ‘M’, ‘d1’);
违反主键约束(实体完整性)
C INSERT INTO Emp VALUES(‘e001’, ‘王’, ‘M’, NULL);
D INSERT INTO Emp VALUES(‘e001’, ‘王’, ‘X’, ‘d1’);
违反 CHECK 约束,只能是M或者F
Emp 表约束:
Eno CHAR(4)→ 必须提供值(字符型)。PRIMARY KEY (Eno)→ 不能为空,不能重复。Esex CHAR(1) CHECK(Esex IN (‘M’, ‘F’))→ 只能是 M 或 F,注意字符串格式。EDno CHAR(4) REFERENCES Dept(Dno)→ 外键约束。当前Dept表是空的没有数据,所以插入非空EDno会违反外键约束,只能插入NULL(假设允许为空)。
SQLCA/游标/指示变量/动态SQL
12.嵌入式 SQL 中,将记录的属性值赋给主变量时,若属性为空值,而主变量不能空值,为解决这一矛盾,使用的机制是()。
A SQLCA
通信区,记录 SQL 语句执行的整体状态信息(如错误码、警告)
B 游标
用于处理多行查询结果
C 指示变量
数据库:可以存储 NULL,表示“未知”或“不存在”。
主语言(C、Java 等):普通变量没有 NULL 的概念。比如 C 语言的 int,要么是 0,要么是某个整数,无法表示“空值”。
指示变量告诉程序没有值,先保持原数据
D 动态SQL 运行时动态构造 SQL 语句,用于处理不确定的查询结构
21-23
嵌入式SQL中通过( 主变量 )实现主语言与SQL语句间进行参数传递;SQL语句的执行状态通过 ( SQLCA ) 传递给主语言来进行流程控制;对于返回结果为多条记录的SQL语句,通过 ( 游标 ) 来由主语言逐条处理。
59-60
嵌入式SQL中,若查询结果为多条记录时,将查询结果交予主语言处理时, 应使用的机制是( 游标),引入( 指示变量 )来解决主语言无空值的问题。
聚簇索引
13.要实现记录的物理顺序与索引项次序一致,应选择的索引类型是()。
A. HASH 索引:基于哈希函数将键值映射到桶中,数据的物理存储与键值顺序没有关系,查找时通过哈希值快速定位,不涉及排序。 ❌
B. 聚簇索引:索引的逻辑顺序与数据的物理顺序一致 ✅
把逻辑上相关的数据,物理上“聚”到一起
就像《新华字典》的正文,所有汉字(数据行)本身就是按照拼音字母(索引键)的顺序,从 A 到 Z 实实在在排版装订的。减少查询需要的IO,提供效率。
C. B+树索引:
非聚簇的 B+树索引,叶子节点存储的是指向数据行的指针(或主键),数据的物理顺序可以与索引顺序不同
只有在建立聚簇索引时如果使用 B+树结构,才具有聚簇特性
题干强调的是“物理顺序一致”这个特性,而非树结构本身。 ❌
D. 单一索引:指索引键只有一个属性列,与数据的物理存储顺序无关。 ❌
题库2.5
在SQL中,能够改变基本表中元组的物理存储位置的方法是( )。
B 使用CLUSTER索引
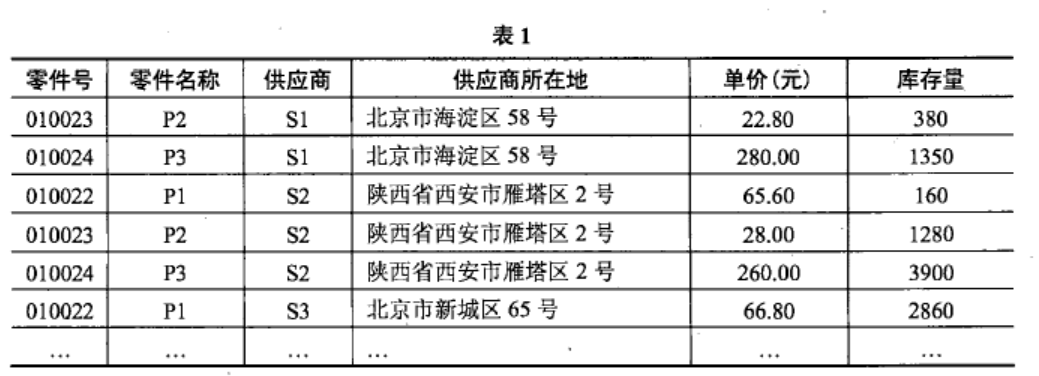
14.15.某销售公司数据库的零件P(零件号,零件名称,供应商,供应商所在地,单价,库存量)关系如表1所示,
其中同一种零件可由不同的供应商供应,一个供应商可以供应多种零件。
零件关系的主键为 ( 零件号/供应商 ) ,该关系存在冗余以及插入异常和删除异常等问题。为了解决这一问题需要将零件关系分解为 ( 15 ) 。
对零件关系P,查询各种零件的平均单价、最高单价与最低单价之间差价的SQL语句为:
SELECT 零件号, ( 16 )
FROM P
( 17 ) ;
对零件关系 P,查询库存量大于等于 100 小于等于 500 的零件“P1”的供应商及库存量,要求供应商地址包含“西安” 。实现该查询的SQL语句为:
SELECT 零件名称,供应商名,库存量
FROM P
WHERE ( 18 ) AND ( 19 ) ;
请作答:第 15 题
原始关系:P(零件号,零件名称,供应商,供应商所在地,单价,库存量)
主键:(零件号,供应商)
零件号 → 零件名称
供应商 → 供应商所在地
(零件号,供应商)→ 单价
(零件号,供应商)→ 库存量
A P1(零件号,零件名称,单价) 、P2(供应商,供应商所在地,库存量)
单价不依赖于零件号
B P1(零件号,零件名称) 、P2(供应商,供应商所在地,单价,库存量)
零件号和供应商才是主键,P2缺失了
C P1(零件号,零件名称) 、P2(零件号,供应商,单价,库存量)、P3(供应商,供应商所在地)
D P1(零件号,零件名称)、P2(零件号,单价,库存量)、P3(供应商,供应商所在地)、P4(供应商所在地,库存量)
应该保留完全依赖于主键(零件号,供应商)的属性:(零件号,供应商,单价,库存量),况且供应商所在地和库存量没有关系
非聚合字段
SELECT 零件号, ( 16 )
FROM P
( 17 ) ;
请作答:第 16 题
A零件名称,AVG(单价),MAX(单价)− MIN(单价)
B供应商,AVG(单价),MAX(单价)− MIN(单价)
聚合函数肯定带有括号,排除CD
C零件名称,AVG 单价,MAX 单价− MIN 单价
D供应商,AVG 单价,MAX 单价 − MIN 单价
请作答:第 17 题
A ORDER BY 供应商
B ORDER BY 零件号
C GROUP BY 供应商
D GROUP BY 零件号
16/17题联系起来看:
聚合列:使用了聚合函数的列,如 SUM(sales), COUNT(*), AVG(score)
非聚合列:直接列出的原始列,如 product_name, department
只要 SELECT 里出现了 AVG(单价) 这样的聚合函数:
SQL 就要求必须对所有非聚合字段(普通列)进行分组,所以必须有Group By
GROUP BY 零件号 之后,组内情况:
┌──────────┬──────────┬──────────┐
│ 零件号 │ 零件名称 │ 单价 │
├──────────┼──────────┼──────────┤
│ 010023 │ P2 │ 22.80 │
│ 010023 │ P2 │ 28.00 │ ← 名称都叫 P2,固定不变
├──────────┼──────────┼──────────┤
│ 010024 │ P3 │ 280.00 │
│ 010024 │ P3 │ 260.00 │ ← 名称都叫 P3,固定不变
└──────────┴──────────┴──────────┘为什么是group by零件号?因为零件号相同的零件型号相同,不管来自哪个供应商,我们先选出对应型号的零件再去比价才是符合需求的。
其次,零件号 → 零件名称
如果我们select 供应商,再group by 供应商,那零件号这个非聚合列就没有被分组,这是不允许的。而零件名称和零件号有依赖关系,可以select 零件名称再group by零件号。
SELECT 零件名称,供应商名,库存量
FROM P
WHERE ( 18 ) AND ( 19 ) ;
请作答:第 18 题
A零件名称= ‘P1’ AND库存量Between 100 AND 500
B零件名称= ‘P1’ AND库存量Between 100 TO 500
没有 TO 这种用法
请作答:第 19 题
A供应商所在地in ‘%西安%’
IN 是精确匹配列表
B供应商所在地like ‘__西安%’
意思是西安的前面恰好只有两个任意字符
C供应商所在地like ‘%西安%’
D供应商所在地like ‘西安%’
必须以"西安"开头
视图/数据字典的概念
20.关于视图的叙述,错误的是( ) 。
A视图不存储数据,但可以通过视图访问数据
视图本身不存储数据,只是一个保存好的查询定义。通过视图查询时,数据库会动态执行背后的 SELECT 语句访问真实数据,所以“不存数据但能访问数据”完全正确。
B视图提供了一种数据安全机制
视图是重要的数据安全手段。你可以给用户开放视图的访问权限,但隐藏底层表的敏感列(如工资),实现数据隔离。
C视图可以实现数据的逻辑独立性
当底层表结构改变时,只要调整视图的定义,应用程序看到的视图不变,程序代码就不需要修改。
D视图能够提高对数据的访问效率
视图是逻辑层面的虚拟表,本身不会像索引那样带来物理上的查询加速。它只是把一条复杂的 SQL 预先存好,底层运行速度仍取决于原表上的索引。
40-41
在数据库系统中,当视图创建完毕后,数据字典中保存的是(视图定义 )。事实上,视图是一个( 虚拟表,查询时可以从一个或者多个基本表或视图中导出的表 )。
数据字典:是数据库的系统目录,是一组系统自动维护的表。它记录着整个数据库的元数据,比如有哪些表、有哪些用户、有哪些视图、有哪些索引等。
题库2.8
以下关于视图的叙述中,错误的是( )。
A视图是虚表 ✅ 视图只存储定义,不存储数据。
B视图可以从视图导出 ✅ 可以基于已有视图再创建新视图。
C视图的定义存放在数据库中 ✅ 定义存储在数据字典中
D所有视图都可以更新
包含 GROUP BY、聚合函数、DISTINCT、多表连接等的视图通常不可更新。
题库2.10
“授予用户WANG对视图Course的查询权限“功能的SQL语句是( )。
A GRANT SELECT ON TABLE Course TO WANG
B GRANT SELECT ON VIEW Course TO WANG 注意题目问的是视图
26.某高校的管理系统中有学生关系为:学生(学号,姓名,性别,出生日期,班级),该关系的数据是在高考招生时从各省的考生信息库中导入的,来自同一省份的学生记录在物理上相邻存放,为适应高校对学生信息的大量事务处理是以班级为单位的应用需求,应采取的优化方案是( )。
C对班级建立CLUSTER 索引
聚簇索引(CLUSTER索引)将索引项取值相同的记录在物理上相邻存储,即可减少查询所涉及的I/O操作,可提高查询效率。
存储过程
27.数据库应用系统通常会提供开发接口。若出于安全性考虑,对于只读数据,通常提供( 视图 )以供外部程序访问;
对于需要更新的数据,则以( 28 )的方式供外部调用,并由提供者完成对系统中多个表的数据更新。
请作答:第 28 题
A基本表
直接暴露给外界是不安全的
B视图
不能或者只能更新单个表
C存储过程:把一段流程(过程),存在数据库里,供随时调用。
D触发器
只在特定事件发生时自动执行 ×
56-58
56.57.58.数据库的安全机制中,通过GRANT语句实现的是( 用户授权 );通过建立( 视图 ) 使用户只能看到部分数据,从而保护了其他数据;通过提供( 存储过程 )供第三方开发人 员调用进行数据更新,从而保证数据库的关系模式不被第三方所获取。
69
将存储过程p1的执行权限授予用户U2的SQL语句为。
GRANT( EXECUTE )ON PROCEDURE Pl TO U2;
70
在数据库应用系统开发过程中,常采用 ( 存储过程 )来实现对数据库的更新操作,其内部以事务程序的方式来编写。
82
以下对存储过程的叙述中,不正确的是( )。
A存储过程可以定义变量
在存储过程中,可以使用 DECLARE 定义局部变量
B存储过程是一组为了完成特定功能的SQL语句组成的程序
C存储过程不能嵌套调用
D存储过程可以一次编译,多次执行
89
将具有特定功能的一段SQL语句(多于一条)在数据库服务器上进行预先定义并编译,以供应用程序调用,该段SQL程序可被定义为( 存储过程 )。
96
关于存储过程,下面说法中错误的是( )。
A存储过程可用于实施企业业务规则
B存储过程可以有输入输出参数 存储过程可以定义 IN、OUT、INOUT 类型的参数
C存储过程可以使用游标
D存储过程由数据库服务器自动执行
106
在数据库中新建存储过程的关键字是( )。
A CREATE PROCEDURE
B INSERT PROCEDURE
C CREATE TRIGGER
D INSERT TRIGGER
题库2.11
以下关于存储过程的说法中,错误的是( )。
A存储过程可以有参数✅ 可以定义 IN、OUT、INOUT 参数。
B存储过程可以使用游标✅ 用于逐行处理查询结果。
C存储过程可以调用触发器
要记住触发器只能自动触发
D存储过程是数据库对象✅ 属于模式对象,存储在数据字典中。
29.30.将表employee中name列的修改权限赋予用户Liu,并允许其将该权限授予他人,应使用的SQL语句为:
GRANT( UPDATE(name) )ON TABLE employee TO Liu( 30 );
请作答:第 30 题
A FORALL 批量数据操作,和权限无关
B CASCADE
C WITH GRANT OPTION
D WITH CHECK OPTION
31.以下的SQL 语句,Student与Person之间的关系是( )。
CREATE TYPE Person(
name char(20),
address varchar(50));
CREATE TYPE Student(
under Person
(degree char(20)
department char(20));
A类型继承 子类型继承父类型的属性
B类型引用
一个类型中嵌套引用另一个类型(如 Student 里有个 Person 类型的字段)
C表继承
创建表时基于另一个表来继承结构
32-38.某销售公司数据库的零件关系P(零件号,零件名称,供应商,供应商所在地,库存量),函数依赖集F={零件号→零件名称,(零件号,供应商)→库存量,供应商→供应商所在地}。零件关系P的主键为( 零件号,供应商 ),该关系模式属于( 33 )。
查询各种零件的平均库存量、最多库存量与最少库存量之间差值的SQL语句如下:
SELECT 零件号,( 34 )
FROM P
( 35 );
查询供应商所供应的零件名称为P1或P3,且50≤库存量≤300以及供应商地址包含“雁塔路”的SQL语句如下:
SELECT零件名称,供应商,库存量
FROM P
WHERE ( 36 )AND 库存量 ( 37 )AND 供应商所在地 ( 38 );
33题:
可以得出零件名称和供应商所在地都部分依赖于码,所以关系模式属于1NF。
34题:
AVG(库存量)AS平均库存量,MAX(库存量)-MIN(库存量)AS差值
35题:
GROUP BY零件号
Where子句加括号(运算优先级)
请作答:第 36 题
C 零件名称=’P1’ OR零件名称=’P3’
D(零件名称=’P1’ OR零件名称=’P3’)
这里要注意题目中跟着一个AND运算,AND 优先于 OR,如果不加括号会变成零件名称=’P3’跑去和库存量运算
37题:
Between 50 AND 300
38题:
like’%雁塔路%’
39.引入索引的目的是为了( )。
A.提高查询语句执行效率
B. 实现数据的物理独立性 ❌ 物理独立性由模式/内模式映像实现。
索引属于内模式,但索引本身不是用来实现物理独立性的
C. 提高更新语句执行效率 ❌ 索引反而会降低增删改速度,因为要维护索引。
D. 实现数据的逻辑独立性 ❌ 逻辑独立性由外模式/模式映像实现。
交集UNION并集INTERSECT
42-46.假定学生Students和教师Teachers关系模式如下所示:
Students(学号,姓名,性别,类别,身份证号)
Teachers(教师号,姓名,性别,身份证号,工资)
a.查询在读研究生教师的平均工资、最高与最低工资之间差值的SQL语句如下:
SELECT ( 42 ) FROM Students,Teachers WHERE( 43 );
b.查询既是研究生,又是女性,且工资大于等于3500元的教师的身份证号和姓名的SQL语句如下:
(SELECT 身份证号,姓名
FROM Students
WHERE( 44 ))
( 45 )
(SELECT身份证号,姓名
FROM Teachers
WHERE( 46 ))
42:
AVG(工资) AS 平均工资,MAX(工资)-MIN(工资) AS差值
43:
关联条件:这个人是教师,同时也是学生,两张表通过 身份证号 关联起来,表示是同一个人。
筛选条件:在学生表中,这个人的 类别 = '研究生'(在读研究生)。
Students.身份证号 = Teachers.身份证号 AND Students.类别 =‘研究生’
44-46题:
请作答:第 44 题
A 工资>=3500
B 工资>=‘3500’ 第一张表根本没有工资这个属性
C 性别=女 AND 类别=研究生
D 性别=‘女’ AND 类别=‘研究生’
前半部分:从 Students 表中找出符合条件的学生(研究生、女性)
后半部分:从 Teachers 表中找出符合条件的教师(工资 >= 3500)
中间用集合操作符连接,取两部分的交集(同一个人既是研究生又是教师)
请作答:第 45 题
A EXPERT
B INTERSECT 取交集
C UNION 取并集,
D UNIONALL
46题:
A 工资>=3500
B 工资>=‘3500’ 数值而非字符比较
47.将Students表的查询权限授予用户U1和U2,并允许该用户将此权限授予其他用户。实现此功能的SQL语句如下( )。
B GRANT SELECT ON TABLE Students TO U1,U2 WITH PUBLIC
不存在with public这个用法,只有to public把权限给所有人
C GRANT SELECT TO TABLE Students ON U1,U2 WITH GRANT OPTION
D GRANT SELECT ON TABLE Students TO U1,U2 WITH GRANT OPTION
Alter/删除约束
48.删除表上一个约束的SQL语句中,不包含关键字( )。
A ALTER
B DROP
C DELETE
D TABLE
删除约束的语句格式如下:
ALTER TABLE 表名 DROP CONSTRAINT 约束名。
ALTER [对象类型] [对象名称] [具体操作];
49-53.假定某企业根据2014年5月员工的出勤率、岗位、应扣款得出的工资表如下:
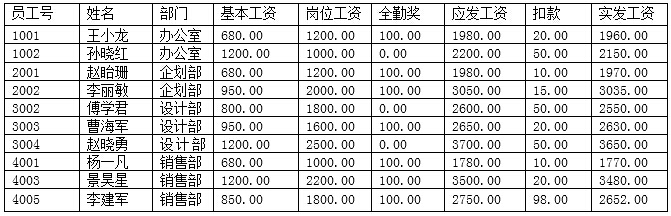
a.查询部门人数大于2的部门员工平均工资的SQL语句如下:
SELECT ( 49 )
FROM工资表
( 50 )
( 51 )
b.将设计部员工的基本工资增加10%的SQL语句如下:
Update 工资表
( 52 )
( 53 );
请作答:第 49 题
A 部门,AVG (应发工资)AS平均工资
B 姓名,AVG (应发工资)AS平均工资
"我查的是'每个什么'的平均工资?"
题干关键词就是答案
"各部门的平均工资" SELECT 部门
"每个员工的平均工资" SELECT 姓名
"各种零件的平均单价" SELECT 零件号
"各种商品的总库存" SELECT 商品名
请作答:第 50 题
C GROUP BY 姓名
D GROUP BY 部门
从第二个选项有group by也能看出来应该选部门,否则没有分组意义
HAVING COUNT/执行顺序
请作答:第 51 题
where是不可以搭配聚合函数用的!!而且不应该在group by之后执行
A WHERE COUNT(姓名)> 2
B WHERE COUNT(DISTINCT(部门))> 2
C HAVING COUNT(姓名)> 2
D HAVING COUNT(DISTINCT(部门))> 2
HAVING 是专门用来对分组后的结果进行筛选的子句,它必须跟在 GROUP BY 后面使用。DISTINCT 在这里的意思是:只计算不重复的项目号,忽略重复值。
数据库真正执行这些子句的顺序是:
SELECT 列1, 聚合函数(列2)
FROM 表
WHERE 原始行条件 -- 可选:分组前筛选
GROUP BY 列1
HAVING 聚合函数条件 -- 分组后筛选
ORDER BY 列1; -- 可选:排序
FROM → WHERE → GROUP BY → HAVING → SELECT → ORDER BY52:
Set基本工资=基本工资*1.1
53:
WHERE部门='设计部'
86
对分组查询结果进行筛选的是( ),其条件表达式中可以使用聚集函数。
A WHERE 子句
B GROUP BY 子句
C HAVING 子句
D ORDER BY 子句
97
在数据库管理系统中,以下SQL语句书写顺序正确的是( )。
SELECT→FROM→WHERE→GROUP BY
题库2.6
对于不包含子查询的SELECT语句,聚集函数不允许出现的位置是( where)。
唯一值索引
54.55.能实现UNIQUE约束功能的索引是( 54 );针对复杂的约束,应采用( 55 ) 来实现。
请作答:第 54 题
A普通索引 只是加快查询速度
B聚簇索引 决定数据的物理存储顺序
C唯一值索引 在索引创建时就会检查唯一性
D复合索引 多列组成的索引,主要还是为了加速多条件查询
触发器
请作答:第 55 题
A存储过程 可以写复杂逻辑,但不会自动执行
B触发器 自动触发,专门用于实施复杂的完整性约束
C函数 主要用于计算并返回值,不适合做完整的约束检查
D多表查询 只是查询手段,根本不能用来"约束"数据
触发器之所以能强制实现数据的完整性和一致性,是因为它可以在数据变更的瞬间自动执行一段程序,检查任何你想要的规则,不符合就拒绝操作,强制回滚
83
以下对触发器的叙述中,不正确的是( )。
A触发器可以传递参数
触发器由事件自动触发,不能像存储过程那样接受外部传入的参数。
B触发器是SQL语句的集合
C用户不能调用触发器
D可以通过触发器来强制实现数据的完整性和一致性
88
以下有关触发器的叙述中,不正确的是( )。
A 触发器可以执行约束、完整性检查
B 触发器中不能包含事务控制语句
触发器是被外部语句(如 INSERT)触发执行的,它和触发它的语句共享同一个事务。因此触发器内部不能使用 COMMIT 或 ROLLBACK
C 触发器不能像存储过程一样,被直接调用执行
D 触发器不能在临时表上创建,也不能引用临时表
有的DBMS可以
90
下面说法错误的是( )。
A存储过程中可以包含流程控制
B存储过程被编译后保存在数据库中
C用户执行SELECT语句时可以激活触发器
触发器只能由 INSERT、UPDATE、DELETE 这三种事件激活
D触发器由触发事件激活,并由数据库服务器自动执行
95
关于触发器, 下面说法中正确的是( )。
A 触发器可以实现完整性约束
B 触发器不是数据库对象 触发器属于模式对象(Schema Object),和表、视图、存储过程一样,记录在数据字典中
C 用户执行SELECT语句时可以激活触发器
D 触发器不会导致无限触发链 没有设置递归深度限制或不做条件退出,就可能形成无限递归
105
以下关于触发器的说法中,错误的是( )。
A 触发器可以带参数
触发器由事件自动触发,不能像存储过程那样接受外部传入的参数。
B 触发器不能被应用程序显式调用
触发器是数据库自动执行的,不能用 CALL 手动调用。
C 触发器可以关联到基本表
触发器通常定义在基本表上,在 INSERT、UPDATE、DELETE 时触发。
D 一个基本表上可以定义多个触发器
题库2.2
以下关于触发器的说法中,错误的是( )。
A 触发器用于实现一些复杂的业务规则
B 触发器内部可以使用事务控制语句
同88题:触发器是被外部语句(如 INSERT)触发执行的,它和触发它的语句共享同一个事务。因此触发器内部不能使用 COMMIT 或 ROLLBACK
C 触发器只能被动触发,不能直接调用
D 触发器内部不能使用DDL语句
不允许执行 CREATE、ALTER、DROP 等 DDL 数据定义语句,因为不可以事物控制,这些语句有隐形的事物提交
题库2.3
在行级触发器中,只有( )语句的条件表达式值为真,触发器才会触发。
A referencing 定义过渡变量
B when
C if 在触发器体内部做流程控制,不是触发条件
D for each row 声明这是行级触发器,不是条件
题库2.4
触发器涉及到的激发事件不包括( )。
A SELECT
B UPDATE
C DELETE
D INSERT
题库2.12
以下关于触发器的说法中,正确的是( )。
由增删改事件激活,自动执行
题库2.13
某数据库中有会员卡基本信息表(含余额信息)和消费记录表,现在需要通过触发器实现“新增消费记录后自动更新会员表的余额属性” ,采用( )触发器比较适合。
“新增消费记录后自动更新余额”这个需求中,更新余额必须在消费记录已经成功插入之后进行
A行级前 此时数据还未插入
B行级后 插入一行后立即用该行的消费金额去更新会员卡的余额
C语句级前 一次插入多条消费记录时只触发一次
D语句级后 一次插入多条消费记录时只触发一次
REFERENCES约束/CHECK
61-64.某医院住院部信息系统中有病人表R(住院号,姓名,性别,科室号,病房,家庭住址),
“住院号”唯一标识表R中的每一个元组,
“性别”的取值只能为M或F,
“家庭住址”包括省、市、街道、邮编,
要求科室号参照科室关系D中的科室号;
科室关系D(科室号,科室名,负责人,联系电话),“科室号”唯一标识关系D中的每一个元组。
a.创建关系R的SQL语句如下:
CREATE TABLE R(住院号CHAR(8) ( 61 ),
姓名CHAR(10),
性别CHAR(1) ( 62 ),
科室号CHAR(4),
病房CHAR(4),
家庭住址ADDR, //ADDR为用户定义的类
( 63 ) );
b.表R中复合属性是( 64 )。
请作答:第 61 题
A PRIMARY KEY
B REFERENCES D(科室号)
外键约束确实是加在"引用方",一般来说是和外键KEY一起写的,也可以写在字段后面,效果一样的。要综合其它选项看。
FOREIGN KEY (本表列名) REFERENCES 外表名(外表列名)
请作答:第 62 题
C CHECK('M','F')
D CHECK(性别IN('M','F'))
CHECK 是约束关键字
括号内是判断条件,CHECK(表达式),这个表达式的计算结果必须是 TRUE 或 FALSE
IN ('M', 'F') 表示取值必须是 M 或 F
63:FOREIGN KEY(科室号)REFERENCES D(科室号)
64:家庭住址
65.下列SQL语句中,能够实现“收回用户ZHAO对学生表(STUD)中学号(XH)的修改权”这一功能的是( ) 。
A REVOKE UPDATE(XH) ON STUD TOZHAO
B REVOKE UPDATE(XH) ON STUD TO PUBLIC
C REVOKE UPDATE(XH) ON STUD FROM ZHAO
D REVOKE UPDATE(XH) ON STUD FROM PUBLIC
意图是 GRANT(给),后面就紧跟 TO(给到)。
意图是 REVOKE(收回),后面就紧跟 FROM(从...那里)。
题库2.16
某会员管理系统需要对会员的账户余额进行限制,业务规则是“账户余额不能小于100”。该业务规则可采用( )约束实现。
A NOTNULL
B UNIQUE
C CHECK
D DEFAULT 只能设置默认值
CREATE TABLE 会员(
...
账户余额 DECIMAL(10,2) CHECK(账户余额 >= 100)
);分析子查询嵌套
66-68.某企业部门关系模式Dept(部门号,部门名,负责人工号,任职时间),员工关系模式EMP(员工号,姓名,年龄,月薪资,部门号,电话,办公室)。部门和员工关系的外键分别是( 66 )。
查询每个部门中月薪资最高的员工号、姓名、+部门名和月薪资的SQL查询语句如下:
SELECT员工号,姓名,部门名,月薪资
FROM EMP Y,Dept
WHERE( 67 )AND月薪资=(
SELECT Max(月薪资)
FROM EMP Z
WHERE ( 68 ) )
请作答:第 66 题
负责人工号和部门号
负责人工号 的取值来自员工表的主键(员工号),所以它是 Dept 表的外键,引用 EMP(员工号)。
部门号 的取值来自部门表的主键(部门号),所以它是 EMP 表的外键,引用 Dept(部门号)。
请作答:第 67 题
SELECT员工号,姓名,部门名,月薪资
FROM EMP Y,Dept 实际上是EMP AS Y然后把AS省略了
有的数据区起了别名就必须用,考试情景下也应该用Y代替EMP
Y.部门号=Dept.部门号
根据题目信息,需要查询的是部门的,所以用部门来连接。
这样查询的中间结果中的每一行都是同一个部门。而且仔细阅读题目的话,只有部门号是两张表里名词都相同的。
如果写成 Y.员工号 = Dept.负责人工号,含义就变成了:只查那些自己是部门负责人的员工
请作答:第 68 题
子查询别名 Z:用来计算 Y 所在部门的最高薪资,返回这个数值
外层查询Y:根据返回的薪资,来作为条件筛选出部门薪资最高的员工
SELECT MAX(月薪资)
FROM EMP Z
WHERE (68)
子查询的作用是:找出当前员工所在部门的最高月薪资,然后外层查询用
AND 月薪资 = (子查询结果) 来判断这个员工是不是该部门薪资最高的那个人。A Z.员工号=Y.员工号
意思是,在 EMP 表Z里,找出和 Y 当前行员工号相同的人,那就没意义了,只能找的出一行这样的人,返回他的工资。
D Z.部门号=Y.部门号 ✅ 正确关联,把子查询限制在和外层查询Y同一个部门内
排序
71-73.给定关系模式 SP _P (供应商号,项目号,零件号,数量),查询至少给 3 个(包 含 3 个)不同项目供应了零件的供应商,要求输出供应商号和供应零件数量的总和, 并按供应商号降序排列。
SELECT 供应商号, SUM (数量) FROM SP _P( 71 )( 72 )( 73 )
SELECT [ ALL| DISTINCT ] <列名>[,· · · n]
FROM <表名|视图名> [,· · · n]
[WHERE <条件表达式>]
[GROUP BY <列名> [ HAVING <条件表达式>] ]
[ORDER BY <列名>[ASC|DESC] [,· · · n] ]请作答:第 71 题
不论有没有聚合函数,GROUP BY 必须在 ORDER BY 前面,这是 SQL 的固定语法顺序,这一空只能是group by
A ORDER BY 供应商号
B GROUP BY 供应商号
C ORDER BY 供应商号 ASC
D GROUP BY 供应商号 DESC
请作答:第 72 题
C HAVING (DISTINCT 项目号)> 2 不存在这种直接having的用法
D HAVING COUNT(DISTINCT 项目号)>2
DISTINCT 在这里的意思是:只计算不重复的项目号,忽略重复值。
题目要求找给三个不同项目供应的供应商,肯定不能计重复值
请作答:第 73 题
C ORDER BY 供应商号 DESC
DESC降序 ASC升序(默认)
74.在SQL中,用户( )获取权限。
可通过对象的所有者执行 GRANT 语句
NULL
75.76.NULL 值在数据库中表示( 75 ),逻辑运算UNKNOWN OR TRUE 的结果是( 76 )。
不存在或不知道
TRUE
98
SQL语言中,NULL值代表( )。
A空字符串
B数值0
C空值
D空指针
100
有一进口商品数据表item_info(item_id,item_type,unit_price,item_count),其中item_id是自动编号字段,其他属性可以为NULL。如果用SQL语句:INSERT INTO item_info(unit_price,item_count) VALUES(9.99,150)向数据表中插入元组时,则该元组的item_type属性值为( NULL)。
题库2.7
在SQL中,表达年龄(Sage)非空的WHERE子句为( )。
A Sage<>NULL <>是排除
B Sage!=NULL NULL既然是一个未知值,就不可以用比较运算符
C Sage IS NOT NULL
DBMS和DDL
77.DBMS提供的DDL功能不包含( )。
A安全保密定义功能 (如 GRANT、REVOKE 定义权限)。
B检索、插入、修改和删除功能 属于 DML(数据操纵语言),即 SELECT、INSERT、UPDATE、DELETE,不属于 DDL。 ✅
C数据库的完整性定义功能 (如 PRIMARY KEY、FOREIGN KEY、CHECK 约束的定义)。
D外模式、模式和内模式的定义功能 属于 DDL(定义视图、基本表、索引等)。
DDL(Data Definition Language,数据定义语言) 是用于定义数据库结构和对象的语言.CREATE、ALTER、DROP 等
DBMS 就是管理数据库的软件系统.MySQL等
自定义函数格式
78.79.给定教师关系 Teacher(T_no, T_name, Dept_name, Tel),其中属性T_no、T_name、Dept_name和Tel的含义分别为教师号、教师姓名、学院名和电话。用SQL创建一个“给定学院名求该学院的教师数”的函数如下:
Create function Dept_count(Dept_name varchar(20))
( 78 )
Begin
( 79 )
select count(*)into d_count
from Teacher
where Teacher.Dept_name= Dept_name
return d_count
end
请作答:第 78 题
A returns integer 返回时无须写变量名
B returns d_count integer
CREATE FUNCTION 函数名(参数名 参数类型)
RETURNS 返回值类型
BEGIN
DECLARE 变量名 数据类型; -- 声明局部变量(可选)
-- 函数体(SQL 语句)
RETURN 返回值;
END请作答:第 79 题
C declare integer
D declare d_count integer 再begin后定义,需要声明变量名
80.81.若将 Workers表的插入权限赋予用户User1,并允许其将该权限授予他人,那么对应的SQL语句为“GRANT( 80 ) TABLE Workers TO User1( 81 );”。
请作答:第 80 题
A INSERT
B INSERT ON
GRANT 权限 ON 表 TO 用户
请作答:第 81 题
A FOR ALL 不存在这种用法
B PUBLIC
C WITH CHECK OPTION 用于视图
D WITH GRANT OPTION
ALL/ANY/排除<>
84-85.某企业人事管理系统中有如下关系模式,员工表Emp(eno, ename, age, sal, dname),属性分别表示员工号、员工姓名、年龄、工资和部门名称;部门表Dept(dname, phone),属性分别表示部门名称和联系电话。需要查询其他部门比销售部门(Sales)所有员工年龄都要小的员工姓名及年龄,对应的SQL语句如下:
SELECT ename, age FROM Emp
WHERE age ( 84 )
(SELECT age FROM Emp WHERE dname='Sales')
AND ( 85 )
请作答:第 84 题
A <ALL 小于子查询返回的所有值
B <ANY 小于子查询返回的任意一个值,那么小于最大值就可以满足
C IN 等于子查询中的任意一个值
D EXISTS 子查询存在结果就为真
题干要求查询:其他部门比销售部门(Sales)所有员工年龄都要小的员工,还要排除掉Sales 部门自己
这里的结构是 age < ALL (子查询),后面的一整句select都是子查询,提供所有的年龄
请作答:第 85 题
A dname='Sales' 只要 Sales 部门 ❌
B dname<>'Sales' 排除 Sales 部门 ✅
C dname<'Sales' 按字母顺序(ASCII)比 Sales 小的部门 ❌
D dname>'Sales' 按字母顺序比 Sales 大的部门 ❌
91-94.假设有两个数据库表,product 表和market 表,分别存放商品信息和市场需求信息。对SQL语句: selet * fom product, market where productp. id=markep.id的结果描述正确的是( 91 )。如果想从market表中移除m id为MO3的记录,语句( 92 )是正确的。如果要收回GRANT SELECT ON product to role_A WITH GRANT OPTION语句给role_A赋予的权限,使用语句( 93 )。在product表、market表初始数据不变的情况下,以下SQL语句返回的结果有( 94 )条记录。
SELECT product.p_id
FROM product
WHERE product.p_num>( SELECT sum (market.m_need)
FROM market
WHERE market.p_id = product.p_id);
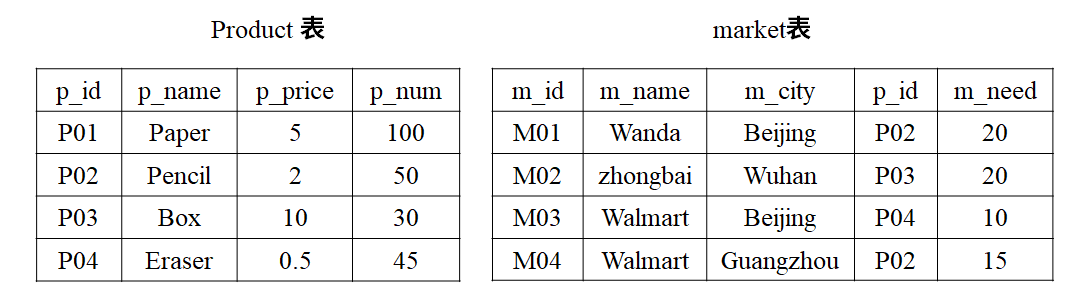
请作答:第 91 题
A查找市场所需商品的信息
B查找所有市场信息
C查找所有商品信息
D查找市场所需的商品信息以及相应的市场需求信息
删除表记录
请作答:第 92 题
A REMOVE FROM market WHERE m id-'MO3'
❌ SQL 中没有 REMOVE
B DROP FROM market WHERE m id-'MO3'
❌ DROP 删除整个表或数据库,不是删除记录,也不能跟 WHERE
C DELETE FROM market WHERE m id='MO3'
✅ 正确语法 DELETE FROM 表名 WHERE 条件
D UPDATE FROM market WHERE m id='MO3'
❌ UPDATE 修改记录,不是删除,且缺少 SET 子句
请作答:第 93 题
A REVOKE SELECT ON product FROM role A
在大多数数据库系统中,RESTRICT 是默认行为。不会生效
B REVOKE SELECT ON product FROM role A CASCADE
C REVOKE SELECT ON product FROM role A WITH GRANT OPTION
D REVOKE SELECT ON product FROM role A ALL 不存在此用法
请作答:第 94 题
SELECT product.p_id
FROM product
WHERE product.p_num > (
SELECT SUM(market.m_need)
FROM market
WHERE market.p_id = product.p_id
);对 product 表的每一行,子查询都会被驱动执行一次:
处理 P01 时,子查询变成:
SUM(m_need) WHERE p_id = 'P01'→ 只算 P01 的需求处理 P02 时,子查询变成:
SUM(m_need) WHERE p_id = 'P02'→ 只算 P02 的需求处理 P03 时,子查询变成:
SUM(m_need) WHERE p_id = 'P03'→ 只算 P03 的需求处理 P04 时,子查询变成:
SUM(m_need) WHERE p_id = 'P04'→ 只算 P04 的需求
计算每个产品的市场需求总量:p_num > 总需求则筛选
P01:没有市场需求 →
SUM = NULLP02:M01(20) + M04(15) → 35
P03:M02(20) → 20
P04:M03(10) → 10
A 0
B 1
C 2
D 3 除了P01其它的都满足Pnum大于需求
99.结构化查询语言(SQL)的出现,极大地促进了( )的应用。
关系数据库
101.假设有两个数据库表insurance和 employee分别记录了某地所有工作人员的社保信息和基本信息:
insurance(id,is_valid),各属性分别表示身份证号、社保是否有效,其中is_valid=1表示社保有效,is_valid=0表示社保无效。
employee(id,name,salay,is_local),各属性分别表示身份证号、姓名、每月工资,户口是否在当地,其中is_local=1表示户口在当地,is_local=0表示户口不在当地。
2021年农历新年,为防控疫情,鼓励留在工作地过年,决定对社保有效且户口不在当地的人群发放津贴。可筛选出满足补贴发放条件人员的SQL语句为( )。
B SELECT * FROM employee, insurance WHERE insurance.is_valid= 1 AND employee.is_local=0 缺少关联条件,两张表会产生笛卡尔积!无法筛选正确行!!
C SELECT * FROM employee, insurance WHERE insurance.id = employee.id AND insurance.is_valid= 1 AND employee.is_local=0
102.在一个数据库中,如果要赋予用户userA可以查询department表的权限,应使用语句( )。
A GRANT SELECT ON department TO userA
C GRANT SELECT ON department FROM userA WITH GRANT OPTION
103.要从数据库中删除people表及其所有数据,以下语句正确的是( )。
A DELETE table people 只删除表中的数据,不删除表结构
B DROP table people 删除整张表
C ERASE table people 不是 SQL 命令,是干扰项。
D ALTER table people 修改表结构
104.
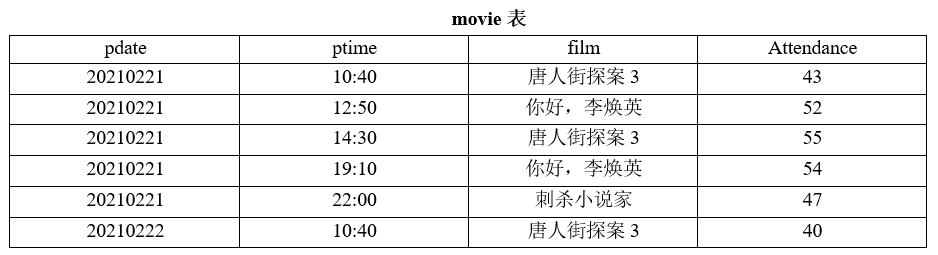
某电影院某日电影入座情况如下表所示。为调整场次,要统计2021年2月21日到场人数总数大于100的电影,可满足要求的SQL语句是( )。A
A
SELECT film,sum(attendance) FROM movie WHERE pdate='20210221' HAVING sum(attendance)>100 缺少分组,同名电影好几场
B
SELECT film,sum(attendance) FROM movie WHERE pdate='20210221' AND attendance>100 GROUP BY film 单场电影根本就没有>100的,要>100的是总人数,用 WHERE 误筛了分组前的每一行,导致空表无结果
C
SELECT film,sum(attendance) FROM movie WHERE pdate='20210221' GROUP BY film HAVING sum(attendance)>100
D
SELECT film,sum(attendance) FROM movie WHERE pdate='20210221' AND sum(attendance)>100 GROUP BY film where不可搭配聚合函数
题库2.9.在SQL中,LIKE后表示任意长度字符串的通配符是(% )。
题库2.15.某应用系统有两个表,会员表Member(M_Id,Mname,Mphone,Mgender,Mage,balance,visible)和消费记录表DeaI(D_Id,Ddate,Dtype,Dvalue,M_Id),其中M_Id为会员编码。如果要查询“陈”姓会员的消费记录,对应的SQL语句为( )。
A
SELECT Mname,Mphone,Ddate,Dvalue FROM Member,Deal WHERE Mname LIKE '% 陈' and Member.M_Id=Deal.M_Id;陈是开头不是结尾
B
SELECT Mname,Mphone,Ddate,Dvalue FRO M Member,Deal WHERE Mname LIKE'陈 %' and Member.M_Id=Deal.M_Id;
C
SELECT Mname,Mphone,Ddate,Dvalue FROM Member,Deal WHERE Member.M_Id=Deal.M_Id; 没有限定条件
D
SELECT Mname,Mphone,Ddate,Dvalue FROM Member,Deal WHERE Mname LIKE'陈 %';没有链接两表,会产生笛卡尔积
SQL数据库概念
题库2.17.以下关于SQL的描述中,正确的是( )。
A SQL只适用于关系型数据库
一些非关系型数据库(如 Hive、Spark SQL、Flink SQL 等大数据处理系统)也提供 SQL 或类 SQL 的查询接口。
B SQL是一种结构化查询语言
C SQL语句不能嵌入到C语句中执行
但绝大多数主流语言都支持嵌入 SQL
D 所有关系型数据库系统都必须支持SQL99标准的所有特性